Let  be a compact smooth manifold and
be a compact smooth manifold and 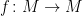 a transitive Anosov
a transitive Anosov 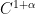 diffeomorphism. If
diffeomorphism. If  is an
is an  -invariant Borel probability measure on that is absolutely continuous with respect to volume, then the Hopf argument can be used to show that is ergodic. In fact, recently it has been shown that even stronger ergodic properties such as multiple mixing can be deduced; for example, see Coudène, Hasselblatt, and Troubetzkoy [Stoch. Dyn. 16 (2016), no. 2].
-invariant Borel probability measure on that is absolutely continuous with respect to volume, then the Hopf argument can be used to show that is ergodic. In fact, recently it has been shown that even stronger ergodic properties such as multiple mixing can be deduced; for example, see Coudène, Hasselblatt, and Troubetzkoy [Stoch. Dyn. 16 (2016), no. 2].
A more general class of measures with strong ergodic properties is given by the theory of thermodynamic formalism developed in the 1970s: given any Hölder continuous potential  , the quantity
, the quantity  is maximized by a unique invariant Borel probability measure
is maximized by a unique invariant Borel probability measure 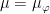 , which is called the equilibrium state of
, which is called the equilibrium state of 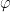 ; the maximum value of the given quantity is the topological pressure
; the maximum value of the given quantity is the topological pressure 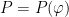 . The unique equilibrium state has the Gibbs property: for every
. The unique equilibrium state has the Gibbs property: for every  there is a constant
there is a constant  such that
such that
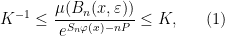
where  is the Bowen ball around
is the Bowen ball around  of order
of order  and radius
and radius  , and we write
, and we write 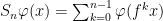 for the th ergodic sum along the orbit of .
for the th ergodic sum along the orbit of .
Historically, strong ergodic properties (mixing, K, Bernoulli) for equilibrium states have been established using methods such as Markov partitions rather than via the Hopf argument. However, in the more general non-uniformly hyperbolic setting, it can be difficult to extend these symbolic arguments, and so it is interesting to ask whether the Hopf argument can be applied instead, even if it only recovers some of the strong ergodic properties. The key property of absolutely continuous measures that is needed for the Hopf argument is the fact that they have a local product structure, which we define below. It was shown by Haydn [Random Comput. Dynam. 2 (1994), no. 1, 79–96] and by Leplaideur [Trans. Amer. Math. Soc. 352 (2000), no. 4, 1889–1912] that in the uniformly hyperbolic setting, the equilibrium states  have local product structure when is Hölder continuous; thus one could apply the Hopf argument to them.
have local product structure when is Hölder continuous; thus one could apply the Hopf argument to them.
This post contains a direct proof that any measure with the Gibbs property (1) has local product structure; see Theorem 3 below. (This will be a bit of a longer post, since we need to recall several different concepts and then do some non-trivial technical work.) Since Bowen’s proof of uniqueness of equilibrium states using specification [Math. Systems Theory 8 (1974/1975), no. 3, 193–202] establishes the Gibbs property, this means that the equilibrium states produced this way could be addressed with the Hopf argument (I haven’t carried out the details yet, so I claim no formal results here). I should point out, though, that even without the use of Markov partitions, Ledrappier showed that these measures have the K property, which in particular implies multiple mixing. Since multiple mixing is the strongest thing we might hope to get from the Hopf argument, my primary motivation for the present approach is that Dan Thompson and I recently generalized Bowen’s result to systems satisfying a certain non-uniform specification property [Adv. Math. 303 (2016), 745–799], and the unique equilibrium states we obtain satisfy a non-uniform version of the Gibbs property (1), so it is reasonable to hope that they also have local product structure and can be studied using the Hopf argument; but this is beyond the scope of this post and will be addressed in a later paper.
1. Local product structure
Before defining local product structure for , we recall some definitions. Since is Anosov, every  has local stable and unstable manifolds
has local stable and unstable manifolds  , which have the following properties.
, which have the following properties.
- There are
 and
and  such that for all ,
such that for all ,  , and
, and 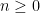 , we have
, we have 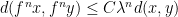 ; a similar contraction bound holds going backwards in time when
; a similar contraction bound holds going backwards in time when  .
.
- There is
 such that if
such that if  for all , then ; similarly for
for all , then ; similarly for  with
with  .
.
- There is such that if
 , then
, then 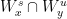 is a single point, which we denote
is a single point, which we denote ![{[x,y]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%2Cy%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Moreover, there is a constant
. Moreover, there is a constant  such that
such that ![{d([x,y],x) \leq Q d(x,y)}](https://s0.wp.com/latex.php?latex=%7Bd%28%5Bx%2Cy%5D%2Cx%29+%5Cleq+Q+d%28x%2Cy%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) , and similarly for
, and similarly for ![{d([x,y],y)}](https://s0.wp.com/latex.php?latex=%7Bd%28%5Bx%2Cy%5D%2Cy%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
A set 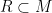 is a rectangle if it has diameter
is a rectangle if it has diameter 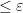 and is closed under the bracket operation: in other words, for every
and is closed under the bracket operation: in other words, for every 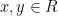 , the intersection point
, the intersection point ![{[x,y] = W_x^s \cap W_y^u}](https://s0.wp.com/latex.php?latex=%7B%5Bx%2Cy%5D+%3D+W_x%5Es+%5Ccap+W_y%5Eu%7D&bg=ffffff&fg=000000&s=0&c=20201002) exists and is contained in
exists and is contained in  .
.
Lemma 1 For every , there is a rectangle containing .
Proof: Write 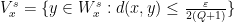 and similarly for
and similarly for  . Consider the set
. Consider the set ![{R = \{[y,z] : y\in V_x^u, z\in V_x^s\}}](https://s0.wp.com/latex.php?latex=%7BR+%3D+%5C%7B%5By%2Cz%5D+%3A+y%5Cin+V_x%5Eu%2C+z%5Cin+V_x%5Es%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and observe that for every
and observe that for every ![{[y,z]\in R}](https://s0.wp.com/latex.php?latex=%7B%5By%2Cz%5D%5Cin+R%7D&bg=ffffff&fg=000000&s=0&c=20201002) we have
we have
![\displaystyle d([y,z],x) \leq d([y,z],y) + d(y,x) \leq (Q+1)d(y,x) \leq \tfrac\varepsilon2.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++d%28%5By%2Cz%5D%2Cx%29+%5Cleq+d%28%5By%2Cz%5D%2Cy%29+%2B+d%28y%2Cx%29+%5Cleq+%28Q%2B1%29d%28y%2Cx%29+%5Cleq+%5Ctfrac%5Cvarepsilon2.+&bg=ffffff&fg=000000&s=0&c=20201002)
Thus has diameter 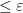 , and for every
, and for every ![{[y,z], [y',z']\in R}](https://s0.wp.com/latex.php?latex=%7B%5By%2Cz%5D%2C+%5By%27%2Cz%27%5D%5Cin+R%7D&bg=ffffff&fg=000000&s=0&c=20201002) we have
we have
![\displaystyle [[y,z],[y',z']] = W_{[y,z]}^s \cap W_{[y',z']}^u = W^s_y \cap W^u_{z'} = [y,z'] \in R,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B%5By%2Cz%5D%2C%5By%27%2Cz%27%5D%5D+%3D+W_%7B%5By%2Cz%5D%7D%5Es+%5Ccap+W_%7B%5By%27%2Cz%27%5D%7D%5Eu+%3D+W%5Es_y+%5Ccap+W%5Eu_%7Bz%27%7D+%3D+%5By%2Cz%27%5D+%5Cin+R%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
so is indeed a rectangle. 
Given and a rectangle 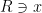 , let
, let  . Then can be recovered from
. Then can be recovered from  via the method in the proof above, as the image of the map
via the method in the proof above, as the image of the map ![{[\cdot,\cdot] \colon V_x^u \times V_x^s \rightarrow M}](https://s0.wp.com/latex.php?latex=%7B%5B%5Ccdot%2C%5Ccdot%5D+%5Ccolon+V_x%5Eu+%5Ctimes+V_x%5Es+%5Crightarrow+M%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Given measures
. Given measures 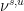 on , let
on , let 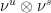 be the pushforward of
be the pushforward of  under this map; that is, for every pair of Borel sets
under this map; that is, for every pair of Borel sets 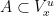 and
and 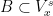 , we put
, we put ![{(\nu^u\otimes \nu^s)(\{[y,z] : y\in A, z\in B\}) = \nu^u(A)\nu^s(B)}](https://s0.wp.com/latex.php?latex=%7B%28%5Cnu%5Eu%5Cotimes+%5Cnu%5Es%29%28%5C%7B%5By%2Cz%5D+%3A+y%5Cin+A%2C+z%5Cin+B%5C%7D%29+%3D+%5Cnu%5Eu%28A%29%5Cnu%5Es%28B%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
Definition 2 A measure has local product structure with respect to 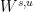 if for every and rectangle there are measures on such that
if for every and rectangle there are measures on such that 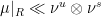 .
.
Theorem 3 Let be a 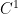 Anosov diffeomorphism,
Anosov diffeomorphism,  a Hölder continuous function, and an -invariant Borel probability measure on satisfying the Gibbs property (1) for some
a Hölder continuous function, and an -invariant Borel probability measure on satisfying the Gibbs property (1) for some  . Then has local product structure in the sense of Definition 2. Moreover, there is
. Then has local product structure in the sense of Definition 2. Moreover, there is 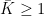 such that for all , the measures can be chosen so that the Radon–Nikodym derivative
such that for all , the measures can be chosen so that the Radon–Nikodym derivative  satisfies
satisfies  at -a.e. point.
at -a.e. point.
A quick side remark: here the diffeomorphism is only required to be . The reason for the hypothesis at the beginning of this post was so that the geometric potential  is Hölder continuous and its unique equilibrium state (the absolutely continuous invariant measure if it exists, or more generally the SRB measure) has the Gibbs property; this may not be true if is only .
is Hölder continuous and its unique equilibrium state (the absolutely continuous invariant measure if it exists, or more generally the SRB measure) has the Gibbs property; this may not be true if is only .
2. Conditional measures
In order to prove Theorem 3, we must start by recalling the notion of conditional measures; see Coudène’s book (especially Chapters 14 and 15) or Viana’s notes for more details than what is provided here.
Let 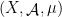 be a Lebesgue space. A partition of
be a Lebesgue space. A partition of  is a map
is a map 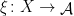 such that for -a.e.
such that for -a.e. 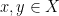 , the sets
, the sets 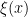 and
and 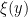 either coincide or are disjoint. Write
either coincide or are disjoint. Write  for the set of partition elements, and say that the partition
for the set of partition elements, and say that the partition  is finite if
is finite if 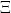 is finite.
is finite.
Given a finite partition , it is easy to define conditional measures 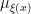 on the set for -a.e. by writing
on the set for -a.e. by writing
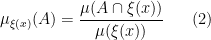
when  , and ignoring those partition elements with zero measure. One can recover the measure from its conditional measures by the formula
, and ignoring those partition elements with zero measure. One can recover the measure from its conditional measures by the formula

If we write  for the measure on defined by putting
for the measure on defined by putting  for all
for all  , then (3) can be written as
, then (3) can be written as
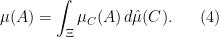
Even when the partition is infinite, one may still hope to obtain a formula along the lines of (4).
Example 1 Let be the unit square, be two-dimensional Lebesgue measure, and be the horizontal line through . Then Fubini’s theorem gives (4) by taking  to be Lebesgue measure on horizontal lines, and defining on , the set of horizontal lines in
to be Lebesgue measure on horizontal lines, and defining on , the set of horizontal lines in ![{[0,1]^2}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%5E2%7D&bg=ffffff&fg=000000&s=0&c=20201002) , in one of the two following (equivalent) ways:
, in one of the two following (equivalent) ways:
- given
 , let
, let  ;
;
- identify with the interval
![{\{0\}\times [0,1]}](https://s0.wp.com/latex.php?latex=%7B%5C%7B0%5C%7D%5Ctimes+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) on the
on the  -axis, and define as the image of one-dimensional Lebesgue measure on this interval.
-axis, and define as the image of one-dimensional Lebesgue measure on this interval.
Note that must satisfy the first of these no matter what the partition is, while the second is a convenient description of in this particular example.
A similar-looking example (and the one which is most relevant for our purposes) comes by letting be a rectangle and letting  be the partition into local unstable leaves. To produce conditional measures
be the partition into local unstable leaves. To produce conditional measures 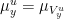 , we need to use the fact that the partition is measurable. This means that there is a sequence of finite partitions
, we need to use the fact that the partition is measurable. This means that there is a sequence of finite partitions 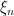 that refines to in the sense that for -a.e. , we have
that refines to in the sense that for -a.e. , we have
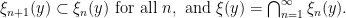
Lemma 4 Given any rectangle , the partition of into local unstable leaves is measurable.
Proof: Fix 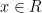 and let
and let 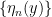 be a refining sequence of finite partitions of
be a refining sequence of finite partitions of  with the property that
with the property that  for all
for all  ; then let
; then let 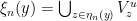 , and we are done.
, and we are done.
Whenever is a measurable partition of a compact metric space , we can define the conditional measures 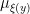 as the limits of the conditional measures
as the limits of the conditional measures 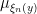 . Indeed, one can show (we omit the proofs) that for -a.e. , the limit
. Indeed, one can show (we omit the proofs) that for -a.e. , the limit 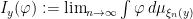 exists for every continuous
exists for every continuous  and defines a continuous linear functional
and defines a continuous linear functional  ; the corresponding measures satisfy
; the corresponding measures satisfy

for every 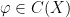 , where once again we put .
, where once again we put .
The key result that we will need to describe properties of 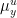 when is the partition of into local unstable leaves is that for -a.e.
when is the partition of into local unstable leaves is that for -a.e.  and every , we have
and every , we have

where is any sequence of finite partitions that refines to .
In order to establish the local product structure for that is claimed by Theorem 3, we will show that the measures vary in an absolutely continuous manner as varies within . That is, we consider for every the holonomy map  defined by moving along local stable manifolds, so
defined by moving along local stable manifolds, so
![\displaystyle \pi_{x,y}(z) = [z,y] = V_z^s \cap V_{y}^u \text{ for all } z\in V_x^u.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cpi_%7Bx%2Cy%7D%28z%29+%3D+%5Bz%2Cy%5D+%3D+V_z%5Es+%5Ccap+V_%7By%7D%5Eu+%5Ctext%7B+for+all+%7D+z%5Cin+V_x%5Eu.+&bg=ffffff&fg=000000&s=0&c=20201002)
Our goal is to use the Gibbs property (1) for to prove that for every rectangle and -a.e. , the conditional measures  and
and  satisfy
satisfy

Once this is established, we can proceed as follows. Consider a rectangle with the decomposition into local unstable manifolds, let be such that (7) holds for -a.e. , and then identify with , as in the second characterization of in Example 1. Let  be the measure on corresponding to under this identification, and let
be the measure on corresponding to under this identification, and let 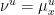 . Given , let
. Given , let ![{\psi_y = \frac{d(\pi_{x,y})_* \mu_x^u}{d\mu_{y}^u} \colon V_y^u \rightarrow [\bar{K}^{-1},\bar{K}]}](https://s0.wp.com/latex.php?latex=%7B%5Cpsi_y+%3D+%5Cfrac%7Bd%28%5Cpi_%7Bx%2Cy%7D%29_%2A+%5Cmu_x%5Eu%7D%7Bd%5Cmu_%7By%7D%5Eu%7D+%5Ccolon+V_y%5Eu+%5Crightarrow+%5B%5Cbar%7BK%7D%5E%7B-1%7D%2C%5Cbar%7BK%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , so that in particular we have
, so that in particular we have
![\displaystyle \int_{V_y^u} \varphi\,d\mu_y^u = \int_{V_y^u} \frac{\varphi}{\psi_y}\, d(\pi_{x,y})_*\mu_x^u = \int_{V_x^u} \frac{\varphi([z,y])}{\psi_y([z,y])} \,d\mu_x^u](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cint_%7BV_y%5Eu%7D+%5Cvarphi%5C%2Cd%5Cmu_y%5Eu+%3D+%5Cint_%7BV_y%5Eu%7D+%5Cfrac%7B%5Cvarphi%7D%7B%5Cpsi_y%7D%5C%2C+d%28%5Cpi_%7Bx%2Cy%7D%29_%2A%5Cmu_x%5Eu+%3D+%5Cint_%7BV_x%5Eu%7D+%5Cfrac%7B%5Cvarphi%28%5Bz%2Cy%5D%29%7D%7B%5Cpsi_y%28%5Bz%2Cy%5D%29%7D+%5C%2Cd%5Cmu_x%5Eu+&bg=ffffff&fg=000000&s=0&c=20201002)
for every continuous  . Then by (5), we have
. Then by (5), we have
![\displaystyle \begin{aligned} \int\varphi\,d\mu &= \int_{\Xi} \int_C \varphi \,d\mu_C \,d\hat\mu(C) = \int_{V_x^s} \int_{V_y^u} \varphi \,d\mu_y^u \,d\nu^s(y) \\ &= \int_{V_x^s} \int_{V_x^u} \frac{\varphi([z,y])}{\psi_y([z,y])} \,d\nu^u(z) \,d\nu^s(y). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%5Cint%5Cvarphi%5C%2Cd%5Cmu+%26%3D+%5Cint_%7B%5CXi%7D+%5Cint_C+%5Cvarphi+%5C%2Cd%5Cmu_C+%5C%2Cd%5Chat%5Cmu%28C%29+%3D+%5Cint_%7BV_x%5Es%7D+%5Cint_%7BV_y%5Eu%7D+%5Cvarphi+%5C%2Cd%5Cmu_y%5Eu+%5C%2Cd%5Cnu%5Es%28y%29+%5C%5C+%26%3D+%5Cint_%7BV_x%5Es%7D+%5Cint_%7BV_x%5Eu%7D+%5Cfrac%7B%5Cvarphi%28%5Bz%2Cy%5D%29%7D%7B%5Cpsi_y%28%5Bz%2Cy%5D%29%7D+%5C%2Cd%5Cnu%5Eu%28z%29+%5C%2Cd%5Cnu%5Es%28y%29.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
By Definition 2, this shows that has local product structure with respect to . Thus in order to prove Theorem 3, it suffices to shows that Gibbs measures satisfy the absolute continuity property (7).
It is worth noting quickly that our use of the term “absolute continuity” here has a rather different meaning from another common concept, which is that of a measure with “absolutely continuous conditional measures on unstable manifolds”. This latter notion is essential for the definition of SRB measures (indeed, in the Anosov setting it is the definition), and involves comparing to volume measure on , instead of to the pushforwards of other conditional measures under holonomy.
3. Adapted partitions
In order to prove the absolute continuity property (7), we need to obtain estimates on . We start by getting estimates on from the Gibbs property (1), and then using these to get estimates on using (6).
We will need a family of partitions of that refines to the partition into points. Fix a reference point  , and suppose we have chosen partitions
, and suppose we have chosen partitions  of
of  and
and 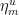 of
of 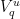 for
for  . Then we can define a partition
. Then we can define a partition 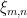 of by taking the direct product of these two partitions, using the foliations of by local stable and unstable leaves: that is, we put
of by taking the direct product of these two partitions, using the foliations of by local stable and unstable leaves: that is, we put
![\displaystyle \xi_{m,n}(y) = \{z\in R : \eta_m^u([z,q]) = \eta_m^u([y,q]) \text{ and } \eta_n^s([q,z]) = \eta_n^s([q,y]) \} \ \ \ \ \ (8)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cxi_%7Bm%2Cn%7D%28y%29+%3D+%5C%7Bz%5Cin+R+%3A+%5Ceta_m%5Eu%28%5Bz%2Cq%5D%29+%3D+%5Ceta_m%5Eu%28%5By%2Cq%5D%29+%5Ctext%7B+and+%7D+%5Ceta_n%5Es%28%5Bq%2Cz%5D%29+%3D+%5Ceta_n%5Es%28%5Bq%2Cy%5D%29+%5C%7D+%5C+%5C+%5C+%5C+%5C+%288%29&bg=ffffff&fg=000000&s=0&c=20201002)
In order to obtain information on 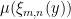 using the Gibbs property (1), we need to put an extra condition on the partitions we use; we need to them to be adapted, meaning that each partition element both contains a Bowen ball and is contained within a larger Bowen ball. Most of the ideas here are fairly standard in thermodynamic formalism, but it is important for us to work separately on the stable and unstable manifolds, then combine the two, so we describe things explicitly. Fix . Given
using the Gibbs property (1), we need to put an extra condition on the partitions we use; we need to them to be adapted, meaning that each partition element both contains a Bowen ball and is contained within a larger Bowen ball. Most of the ideas here are fairly standard in thermodynamic formalism, but it is important for us to work separately on the stable and unstable manifolds, then combine the two, so we describe things explicitly. Fix . Given 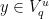 and
and 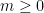 , let
, let

Similarly, given  and , let
and , let
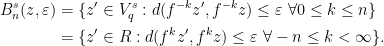
Given  , we say that the partitions are -adapted if for every partition element
, we say that the partitions are -adapted if for every partition element  there is such that
there is such that
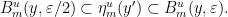
We make a similar definition for using 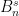 . Note that we can produce an -adapted sequence of partitions as follows:
. Note that we can produce an -adapted sequence of partitions as follows:
- say that
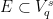 is
is  -separated if for every
-separated if for every 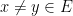 there is
there is  such that
such that 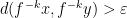 ;
;
- let
 be a maximal -separated set and observe that
be a maximal -separated set and observe that 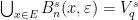 , while the sets
, while the sets  are disjoint;
are disjoint;
- enumerate
 as
as 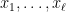 , and build an -adapted partition by considering the sets
, and build an -adapted partition by considering the sets
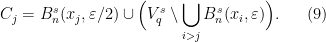
Lemma 5 Let be a measure satisfying the Gibbs property (1). Then there are and 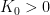 such that if and are -adapted partitions of and , then the product partition defined in (8) satisfies
such that if and are -adapted partitions of and , then the product partition defined in (8) satisfies

for every .
Proof: First we show that the upper bound in (10) holds whenever is sufficiently small. Fix  such that the Gibbs bound (1) holds for Bowen balls of radius
such that the Gibbs bound (1) holds for Bowen balls of radius 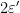 , and such that
, and such that 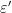 is significantly smaller than the size of any local stable or unstable leaf. It suffices to show that for every we have
is significantly smaller than the size of any local stable or unstable leaf. It suffices to show that for every we have 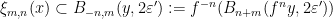 for some , since then (1) gives the upper bound, possibly with a different constant; note that replacing with in the denominator changes the quantity by at most a constant factor, using the fact that is Hölder continuous together with some basic properties of Anosov maps. (See, for example, Section 2 of this previous post for a proof of this Bowen property.)
for some , since then (1) gives the upper bound, possibly with a different constant; note that replacing with in the denominator changes the quantity by at most a constant factor, using the fact that is Hölder continuous together with some basic properties of Anosov maps. (See, for example, Section 2 of this previous post for a proof of this Bowen property.)
Given  such that and lie on the same local stable leaf with
such that and lie on the same local stable leaf with  , let
, let

be the closest that any holonomy along local unstable leaves can bring and . Note that  is positive and continuous in and ; by compactness there is
is positive and continuous in and ; by compactness there is 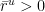 such that
such that 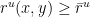 for all
for all  as above. In particular, this means that if are the images under an (unstable) holonomy of some
as above. In particular, this means that if are the images under an (unstable) holonomy of some 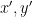 with
with 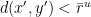 , then we must have
, then we must have  .
.
Choose  similarly for stable holonomies, and fix
similarly for stable holonomies, and fix  . Fix , ,
. Fix , ,  , and
, and 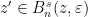 . Then for every
. Then for every 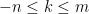 we have
we have
![\displaystyle d(f^k[y',z'],f^k[y,z]) \leq d(f^k[y',z'],f^k[y',z]) + d(f^k[y',z],f^k[y,z]). \ \ \ \ \ (11)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++d%28f%5Ek%5By%27%2Cz%27%5D%2Cf%5Ek%5By%2Cz%5D%29+%5Cleq+d%28f%5Ek%5By%27%2Cz%27%5D%2Cf%5Ek%5By%27%2Cz%5D%29+%2B+d%28f%5Ek%5By%27%2Cz%5D%2Cf%5Ek%5By%2Cz%5D%29.+%5C+%5C+%5C+%5C+%5C+%2811%29&bg=ffffff&fg=000000&s=0&c=20201002)
These distances can be estimated by observing that ![{f^k[y',z']}](https://s0.wp.com/latex.php?latex=%7Bf%5Ek%5By%27%2Cz%27%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and
and ![{f^k[y',z]}](https://s0.wp.com/latex.php?latex=%7Bf%5Ek%5By%27%2Cz%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) are the images of
are the images of 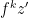 and
and  under a holonomy map along local unstables, and similarly and
under a holonomy map along local unstables, and similarly and ![{f^k[y,z]}](https://s0.wp.com/latex.php?latex=%7Bf%5Ek%5By%2Cz%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) are images of and
are images of and 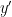 under a holonomy map along local stables. Then our choice of shows that both quantities in the right-hand side of (11) are
under a holonomy map along local stables. Then our choice of shows that both quantities in the right-hand side of (11) are  , which gives the inclusion we needed. This proves the upper bound in (10); the proof of the lower bound is similar.
, which gives the inclusion we needed. This proves the upper bound in (10); the proof of the lower bound is similar.
4. A refining sequence of adapted partitions
Armed with the formula from Lemma 5, we may look at the characterization of conditional measures in (6) and try to prove that the absolute continuity bound (7) holds whenever both satisfy (6). There is one problem before we do this, though; the formula in (6) requires that the sequence of partitions be refining, and there is no a priori reason to expect that the adapted partitions produced by the simple argument before Lemma 5 refine each other. To get this additional property, we must do some more work. To the best of my knowledge, the arguments here are new.
4.1. Strategy
Start by letting 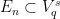 be a maximal
be a maximal 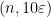 -separated set. We want to build a refining sequence of adapted partitions using the sets
-separated set. We want to build a refining sequence of adapted partitions using the sets 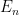 , where instead of using Bowen balls with radius
, where instead of using Bowen balls with radius 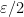 and we will use Bowen balls with radius and
and we will use Bowen balls with radius and 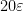 ; this does not change anything essential about the previous section. We cannot immediately proceed as in the argument before Lemma 5, because if we are not careful when choosing the elements of the partition , their boundaries might cut the Bowen balls
; this does not change anything essential about the previous section. We cannot immediately proceed as in the argument before Lemma 5, because if we are not careful when choosing the elements of the partition , their boundaries might cut the Bowen balls  for
for  and
and  , spoiling our attempt to build an adapted partition
, spoiling our attempt to build an adapted partition 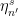 that refines .
that refines .
A first step will be to only build for some values of . More precisely, we fix  such that
such that 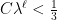 , so that for every and
, so that for every and 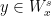 , we have
, we have  ; then writing
; then writing

we have the following for every 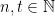 :
:
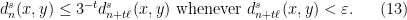
We will only build adapted partitions for those that are multiples of  . We need to understand when the Bowen balls associated to points in the sets can overlap. We write
. We need to understand when the Bowen balls associated to points in the sets can overlap. We write 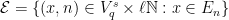 .
.
Definition 6 An -path between 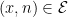 and
and  is a sequence
is a sequence  with
with  and
and 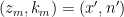 such that
such that 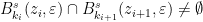 for all
for all  . A subset
. A subset  is -connected if there is an -path between any two elements of
is -connected if there is an -path between any two elements of 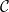 .
.
Given  , let
, let  . In the next section we will prove the following.
. In the next section we will prove the following.
Proposition 7 If 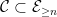 is -connected and
is -connected and 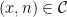 , then
, then

For now we show how to build a refining sequence of adapted partitions assuming (14) by modifying the construction in (9). The key is that we build our partitions so that for every -connected , the set 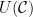 is completely contained in a single element of .
is completely contained in a single element of .
Suppose we have built a partition 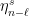 with this property; we need to construct a partition that refines , still has this property, and also has the property that every partition element
with this property; we need to construct a partition that refines , still has this property, and also has the property that every partition element  has some such that
has some such that  . To this end, let
. To this end, let  be an element of the partition , and enumerate the -connected components of
be an element of the partition , and enumerate the -connected components of  as
as  , where each
, where each  contains some
contains some 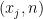 , while each
, while each 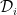 is in fact a subset of
is in fact a subset of  .
.
It follows from (14) that  for all
for all  . Given
. Given 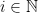 , we can observe that
, we can observe that  for some
for some 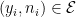 with
with 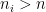 . Moreover, the sets
. Moreover, the sets 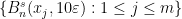 cover , so every
cover , so every 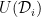 must intersect some set
must intersect some set 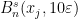 , and hence be contained in some
, and hence be contained in some  . Given , let
. Given , let  . Then for each , let
. Then for each , let  . Define sets
. Define sets 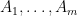 by
by
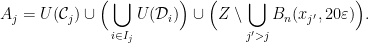
It is not hard to verify that the sets 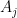 form a partition of such that
form a partition of such that  , and such that every -connected component of that has
, and such that every -connected component of that has 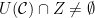 is completely contained in some . Repeating this procedure for the other elements of produces the desired .
is completely contained in some . Repeating this procedure for the other elements of produces the desired .
4.2. Proof of the proposition
Now we must prove Proposition 7. Let 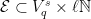 be as in the previous section, so that in particular, every has that is a multiple of , and given any
be as in the previous section, so that in particular, every has that is a multiple of , and given any 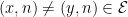 we have
we have  .
.
The following concept is essential for our proof.
Definition 8 Given an -path 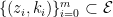 , a ford is a pair
, a ford is a pair 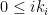 for all
for all 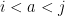 . Think of “fording a river'' to get from
. Think of “fording a river'' to get from 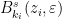 to
to  by going through deeper levels of the -path; the alternative is that
by going through deeper levels of the -path; the alternative is that  for some , in which case
for some , in which case  is a sort of “bridge'' between
is a sort of “bridge'' between 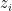 and
and  .
.
Lemma 9 Suppose that is an -path without any fords, and that  for all
for all 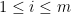 . Then
. Then  .
.
Proof: By the definition of -path, for every 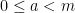 there is a point
there is a point  . Thus
. Thus

where the second inequality uses (13). Now we need to estimate how often different values of 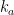 can appear. Let
can appear. Let  ; we claim that for every
; we claim that for every  , we have
, we have

First note that 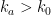 for all
for all 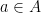 , because otherwise
, because otherwise  would be a ford. Since the -path has no fords, every
would be a ford. Since the -path has no fords, every 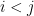 with
with  must be separated by some
must be separated by some  with
with 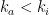 , and we conclude that for every , we have
, and we conclude that for every , we have

For 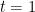 , this establishes (16) immediately. If (16) holds up to
, this establishes (16) immediately. If (16) holds up to  , then this gives
, then this gives

which proves (16) for all by induction. Combining (15) and (16), we have
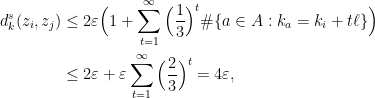
which proves Lemma 9.
Now we show that the  -separation condition rules out the existence of fords entirely.
-separation condition rules out the existence of fords entirely.
Lemma 10 If is an -path, then it has no fords.
Proof: Fix an -path  . Denote the set of fords by
. Denote the set of fords by
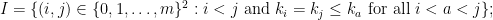
our goal is to prove that  is empty. Put a partial ordering on by writing
is empty. Put a partial ordering on by writing
![\displaystyle (i',j') \preceq (i,j)\ \Leftrightarrow\ [i',j'] \subset [i,j] \ \Leftrightarrow\ i \leq i' < j' \leq j.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%28i%27%2Cj%27%29+%5Cpreceq+%28i%2Cj%29%5C+%5CLeftrightarrow%5C+%5Bi%27%2Cj%27%5D+%5Csubset+%5Bi%2Cj%5D+%5C+%5CLeftrightarrow%5C+i+%5Cleq+i%27+%3C+j%27+%5Cleq+j.+&bg=ffffff&fg=000000&s=0&c=20201002)
If is non-empty, then since it is finite it must contain some element 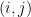 that is minimal with respect to this partial ordering. In particular, the -path
that is minimal with respect to this partial ordering. In particular, the -path  contains no fords, and so by Lemma 9 we have
contains no fords, and so by Lemma 9 we have 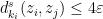 , contradicting the assumption that
, contradicting the assumption that 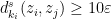 (since
(since  is
is  -separated), and we conclude that must be empty, proving the lemma.
-separated), and we conclude that must be empty, proving the lemma.
Now we prove Proposition 7. Let be -connected and fix 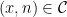 . Given any
. Given any 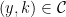 , there is an -path such that and
, there is an -path such that and  . By Lemma 10, this path has no fords, and so Lemma 9 gives
. By Lemma 10, this path has no fords, and so Lemma 9 gives 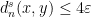 . We conclude that
. We conclude that 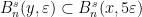 , which proves Proposition 7.
, which proves Proposition 7.
5. Completion of the proof
Thanks to the previous section, we can let and be -adapted partitions of and such that refines whenever 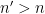 and
and 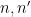 are both multiples of . By Lemma 5, we have good lower and upper estimates on
are both multiples of . By Lemma 5, we have good lower and upper estimates on  for all , where is the product partition defined in (8). By (6), there is
for all , where is the product partition defined in (8). By (6), there is  with
with  such that for every
such that for every  , we have
, we have
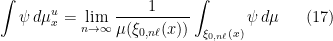
for every continuous  . The next step towards proving Theorem 3 is the following result.
. The next step towards proving Theorem 3 is the following result.
Proposition 11 There is a constant  such that for any
such that for any 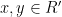 and every continuous
and every continuous  , we have
, we have  , where
, where  is the holonomy map along local unstables.
is the holonomy map along local unstables.
Proof: Start by fixing for each  a set
a set  such that every element of
such that every element of  contains exactly one point in
contains exactly one point in 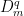 . Then let
. Then let 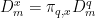 for every .
for every .
Given a positive continuous function  , there is such that if
, there is such that if 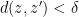 , then
, then 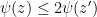 . Thus for all sufficiently large
. Thus for all sufficiently large 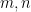 , we have whenever
, we have whenever  . For any such and any , we conclude that
. For any such and any , we conclude that

where we write 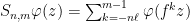 and where the last inequality uses Lemma 5. Similarly,
and where the last inequality uses Lemma 5. Similarly,

and we conclude from (6) that
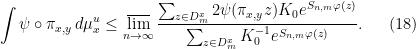
Note that since is Hölder continuous, there are 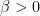 and
and  such that
such that  for all
for all  . Thus given any
. Thus given any  and any , we have
and any , we have

Thus (18) gives
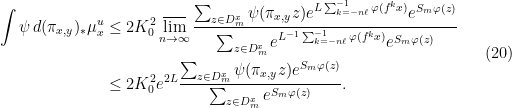
A similar set of computations for shows that

Since 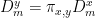 , we can rewrite the sums over
, we can rewrite the sums over 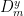 as sums over
as sums over 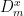 ; for example,
; for example,
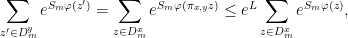
where the inequality uses the fact that the estimate (19) also holds for forward ergodic averages of two points on the same local stable manifold. Using a similar estimate for the numerator in (21) gives
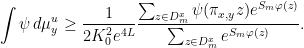
Together with (20), this gives

which completes the proof of Proposition 11.
To complete the proof of Theorem 3, we first observe that for every open set  , there is a sequence of continuous functions
, there is a sequence of continuous functions ![{\psi_n\colon V_y^u \rightarrow (0,1]}](https://s0.wp.com/latex.php?latex=%7B%5Cpsi_n%5Ccolon+V_y%5Eu+%5Crightarrow+%280%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) that converge pointwise to the indicator function
that converge pointwise to the indicator function 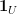 ; applying Proposition 11 to these functions and using the dominated convergence theorem gives
; applying Proposition 11 to these functions and using the dominated convergence theorem gives
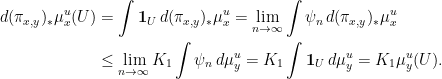
Then for every measurable 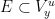 , we have
, we have
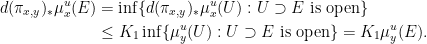
This proves that 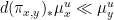 and that the Radon–Nikodym derivative is
and that the Radon–Nikodym derivative is 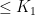 -a.e. The lower bound
-a.e. The lower bound  follows since the argument is symmetric in and . This proves (7) and thus completes the proof of Theorem 3.
follows since the argument is symmetric in and . This proves (7) and thus completes the proof of Theorem 3.

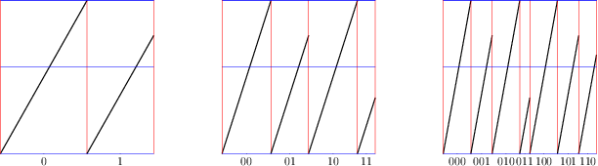
![{f\colon [0,1]\to [0,1]}](https://s0.wp.com/latex.php?latex=%7Bf%5Ccolon+%5B0%2C1%5D%5Cto+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
such that
and
is continuous and strictly monotonic;
is dense in
, where
denotes the set of all endpoints of the intervals
;
;

![\displaystyle \begin{aligned} I(w) &:= J_{w_1} \cap f^{-1}(J_{w_2}) \cap \cdots \cap f^{-(|w|-1)}(J_{w_{|w|}}) \\ &= \{ x\in [0,1] : f^{k-1}(x) \in J_{w_k} \text{ for all } 1\leq k\leq |w| \}. \end{aligned} \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+I%28w%29+%26%3A%3D+J_%7Bw_1%7D+%5Ccap+f%5E%7B-1%7D%28J_%7Bw_2%7D%29+%5Ccap+%5Ccdots+%5Ccap+f%5E%7B-%28%7Cw%7C-1%29%7D%28J_%7Bw_%7B%7Cw%7C%7D%7D%29+%5C%5C+%26%3D+%5C%7B+x%5Cin+%5B0%2C1%5D+%3A+f%5E%7Bk-1%7D%28x%29+%5Cin+J_%7Bw_k%7D+%5Ctext%7B+for+all+%7D+1%5Cleq+k%5Cleq+%7Cw%7C+%5C%7D.+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)

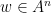
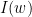

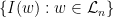
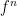

such that
whenever
, and prove that in this case Condition 2 (generating) is satisfied.
, and that there is a semi-conjugacy
defined by
such that
is 1-1.
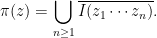
has positive topological entropy
.

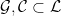
, there are
and
such that
.
such that for every
, there is
with
such that
.
.


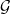
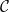


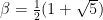
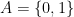
![{I(0) = [0,\frac 1\beta]}](https://s0.wp.com/latex.php?latex=%7BI%280%29+%3D+%5B0%2C%5Cfrac+1%5Cbeta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{I(1) = [\frac 1\beta,1]}](https://s0.wp.com/latex.php?latex=%7BI%281%29+%3D+%5B%5Cfrac+1%5Cbeta%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{F(0) = [0,1] = I(0) \cup I(1)}](https://s0.wp.com/latex.php?latex=%7BF%280%29+%3D+%5B0%2C1%5D+%3D+I%280%29+%5Ccup+I%281%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
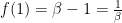
![{F(1) = [0,\frac 1\beta] = I(0)}](https://s0.wp.com/latex.php?latex=%7BF%281%29+%3D+%5B0%2C%5Cfrac+1%5Cbeta%5D+%3D+I%280%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)


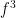
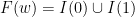
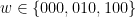
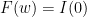

, and
. In particular, we have
for all
that do not contain
as a subword. (Thus




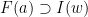
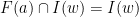

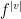
, we have
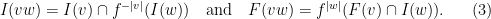
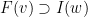 , then
, then  and
and 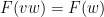 .
. 
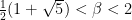

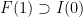


on
is the same as the vertical interval spanned by the graph of
.
, the graph of
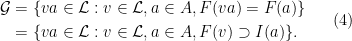
and that
. In particular,
, and
lie in
(at least for the value of
, then
, where
(concatenation with the repeated symbol only appearing once).

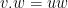
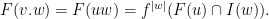
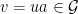
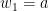
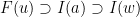
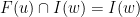
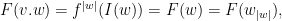
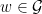


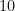




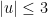
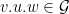
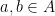
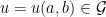


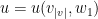
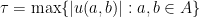
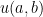

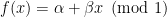
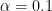
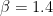


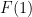
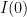

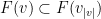
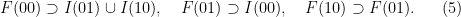
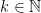
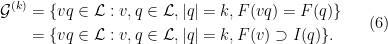
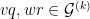 (with
(with 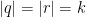 ) have the property that
) have the property that  , then
, then  .
. 

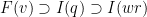
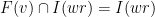
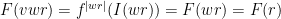



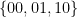
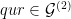
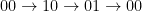
and whose edges are given by the condition that
exactly when
. Say that
if this graph is strongly connected, meaning that given any two
, there is a path in the graph from
to
.


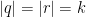
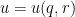

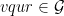
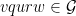




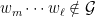

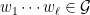

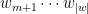

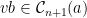
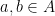
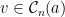
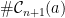



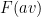

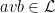




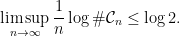
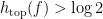

![{(0,\log 2]}](https://s0.wp.com/latex.php?latex=%7B%280%2C%5Clog+2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

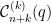
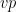
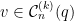
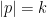


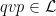
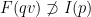
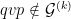

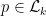

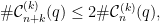
. Then the coding space
tell us anything about having it for other values? (If so, one might hope to be able to remove the condition on

 such that every
such that every  , followed by a `good core’ from
, followed by a `good core’ from 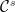 . Formally, for every
. Formally, for every 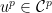 ,
, 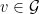 , and
, and  such that
such that 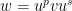 . See [CT] for examples of shift spaces with decompositions satisfying the conditions in the following theorem. (Spoiler:
. See [CT] for examples of shift spaces with decompositions satisfying the conditions in the following theorem. (Spoiler:  -gap shifts.)
-gap shifts.)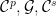 satisfying the following conditions.
satisfying the following conditions. 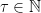 such that for all
such that for all  , there are
, there are  such that
such that 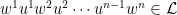 .
.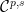 .
.  .
.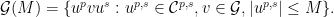
 ; if you are familiar with Pesin theory for non-uniformly hyperbolic diffeomorphisms, it is reasonable to think of this as an analogue of the decomposition of a (non-uniformly) hyperbolic set into regular level sets. (If you are not familiar with Pesin theory, you should probably just ignore that last sentence.) In [CT], we required the following extra condition.
; if you are familiar with Pesin theory for non-uniformly hyperbolic diffeomorphisms, it is reasonable to think of this as an analogue of the decomposition of a (non-uniformly) hyperbolic set into regular level sets. (If you are not familiar with Pesin theory, you should probably just ignore that last sentence.) In [CT], we required the following extra condition.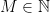 , there exists
, there exists  such that given
such that given 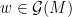 , there exist words
, there exist words 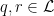 with length
with length 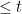 such that
such that 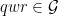 .
.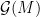 has (a slightly weaker version of) specification as well, with gap size allowed to depend on
has (a slightly weaker version of) specification as well, with gap size allowed to depend on 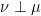 . The proof in [CT] follows similar lines, and roughly speaking, Condition (III) was only required for the second half. More precisely, using only Conditions (I) and (II), [CT] still contains a proof of the following.
. The proof in [CT] follows similar lines, and roughly speaking, Condition (III) was only required for the second half. More precisely, using only Conditions (I) and (II), [CT] still contains a proof of the following. such that
such that ![\displaystyle \mu[w] \geq ce^{-|w| h} \text{ for all } w\in {\mathcal G}. \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmu%5Bw%5D+%5Cgeq+ce%5E%7B-%7Cw%7C+h%7D+%5Ctext%7B+for+all+%7D+w%5Cin+%7B%5Cmathcal+G%7D.+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mu([u] \cap \sigma^{-(|u| + m)}[v]) \geq c e^{-(|u| + |v|) h} \text{ for all } u,v\in {\mathcal G}. \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmu%28%5Bu%5D+%5Ccap+%5Csigma%5E%7B-%28%7Cu%7C+%2B+m%29%7D%5Bv%5D%29+%5Cgeq+c+e%5E%7B-%28%7Cu%7C+%2B+%7Cv%7C%29+h%7D+%5Ctext%7B+for+all+%7D+u%2Cv%5Cin+%7B%5Cmathcal+G%7D.+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
 is allowed to depend on
is allowed to depend on 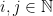 with
with 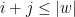 , let
, let
 and last
and last  symbols from
symbols from 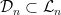 , we will write
, we will write ![{[{\mathcal D}_n] = \bigcup_{w\in {\mathcal D}_n} [w] \subset X}](https://s0.wp.com/latex.php?latex=%7B%5B%7B%5Cmathcal+D%7D_n%5D+%3D+%5Cbigcup_%7Bw%5Cin+%7B%5Cmathcal+D%7D_n%7D+%5Bw%5D+%5Csubset+X%7D&bg=ffffff&fg=000000&s=0&c=20201002) for the union of the corresponding cylinders.
for the union of the corresponding cylinders.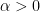 and
and  such that if
such that if  is any MME and
is any MME and ![{\nu([{\mathcal D}_n]) \geq \frac 12}](https://s0.wp.com/latex.php?latex=%7B%5Cnu%28%5B%7B%5Cmathcal+D%7D_n%5D%29+%5Cgeq+%5Cfrac+12%7D&bg=ffffff&fg=000000&s=0&c=20201002) , then there are
, then there are 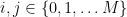 (depending on
(depending on  ) such that
) such that 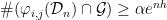 .
.  with any
with any 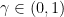 , at the cost of possibly needing to use a different
, at the cost of possibly needing to use a different  and
and 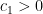 such that if
such that if  , then
, then 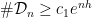 .
.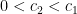 , there exists
, there exists 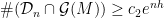 . (The formulation in [CT] is slightly different, but the proof there gives this statement.)
. (The formulation in [CT] is slightly different, but the proof there gives this statement.)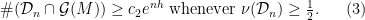
 there are
there are  such that
such that  ; moreover, for any
; moreover, for any  , there are at most
, there are at most 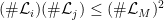 words
words 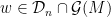 with
with  . It follows that
. It follows that
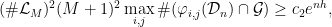
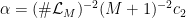 .
. 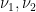 on
on 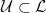 and
and  such that
such that ![{\nu_1([{\mathcal U}_n]) \geq 1-\beta}](https://s0.wp.com/latex.php?latex=%7B%5Cnu_1%28%5B%7B%5Cmathcal+U%7D_n%5D%29+%5Cgeq+1-%5Cbeta%7D&bg=ffffff&fg=000000&s=0&c=20201002) for all
for all ![{\nu_2([\varphi_{i,j} {\mathcal U}_n]) \leq \beta}](https://s0.wp.com/latex.php?latex=%7B%5Cnu_2%28%5B%5Cvarphi_%7Bi%2Cj%7D+%7B%5Cmathcal+U%7D_n%5D%29+%5Cleq+%5Cbeta%7D&bg=ffffff&fg=000000&s=0&c=20201002) for all
for all  satisfying
satisfying  and
and 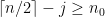 , in particular, for all
, in particular, for all 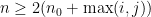 .
. and both are invariant, there are disjoint invariant sets
and both are invariant, there are disjoint invariant sets  such that
such that 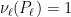 for
for  . By inner regularity there are compact sets
. By inner regularity there are compact sets 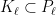 such that
such that 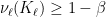 .
.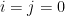 , then one could at this point put
, then one could at this point put ![{{\mathcal U} = \{w\in {\mathcal L} : [w] \cap K_1 \neq \emptyset\}}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathcal+U%7D+%3D+%5C%7Bw%5Cin+%7B%5Cmathcal+L%7D+%3A+%5Bw%5D+%5Ccap+K_1+%5Cneq+%5Cemptyset%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and be done; this is a fairly standard argument and is what we used in [CT], where in fact we did not even bother to spell it out so explicitly. The extension to general
and be done; this is a fairly standard argument and is what we used in [CT], where in fact we did not even bother to spell it out so explicitly. The extension to general  — which is needed in order to leverage Lemma
— which is needed in order to leverage Lemma 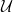 , and this is where [PYY] is quite clever in strengthening the usual argument.)
, and this is where [PYY] is quite clever in strengthening the usual argument.)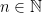 , let
, let ![{{\mathcal U}_n = \{ w \in {\mathcal L}_n : [w] \cap \sigma^{-\lfloor n/2 \rfloor} K_1 \neq \emptyset \}}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathcal+U%7D_n+%3D+%5C%7B+w+%5Cin+%7B%5Cmathcal+L%7D_n+%3A+%5Bw%5D+%5Ccap+%5Csigma%5E%7B-%5Clfloor+n%2F2+%5Crfloor%7D+K_1+%5Cneq+%5Cemptyset+%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . It follows immediately that
. It follows immediately that ![{[{\mathcal U}_n] \supset \sigma^{-\lfloor n/2 \rfloor}K_1}](https://s0.wp.com/latex.php?latex=%7B%5B%7B%5Cmathcal+U%7D_n%5D+%5Csupset+%5Csigma%5E%7B-%5Clfloor+n%2F2+%5Crfloor%7DK_1%7D&bg=ffffff&fg=000000&s=0&c=20201002) , and since
, and since  is invariant we get
is invariant we get![\displaystyle \nu_1[{\mathcal U}_n] \geq \nu_1(\sigma^{-\lfloor n/2 \rfloor} K_1) = \nu_1(K_1) \geq 1-\beta,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cnu_1%5B%7B%5Cmathcal+U%7D_n%5D+%5Cgeq+%5Cnu_1%28%5Csigma%5E%7B-%5Clfloor+n%2F2+%5Crfloor%7D+K_1%29+%3D+%5Cnu_1%28K_1%29+%5Cgeq+1-%5Cbeta%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
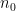 large enough that no
large enough that no  (this is possible since these are compact disjoint sets). Then for every
(this is possible since these are compact disjoint sets). Then for every  , the word
, the word 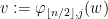 has
has ![{[v] \supset \sigma^{\lfloor n/2 \rfloor} [w]}](https://s0.wp.com/latex.php?latex=%7B%5Bv%5D+%5Csupset+%5Csigma%5E%7B%5Clfloor+n%2F2+%5Crfloor%7D+%5Bw%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , which intersects
, which intersects ![{[v] \cap K_1 \neq \emptyset}](https://s0.wp.com/latex.php?latex=%7B%5Bv%5D+%5Ccap+K_1+%5Cneq+%5Cemptyset%7D&bg=ffffff&fg=000000&s=0&c=20201002) , and moreover
, and moreover 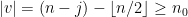 , so
, so ![{[v] \cap K_2 = \emptyset}](https://s0.wp.com/latex.php?latex=%7B%5Bv%5D+%5Ccap+K_2+%3D+%5Cemptyset%7D&bg=ffffff&fg=000000&s=0&c=20201002) ; that is,
; that is, ![{[v] \subset K_2^c}](https://s0.wp.com/latex.php?latex=%7B%5Bv%5D+%5Csubset+K_2%5Ec%7D&bg=ffffff&fg=000000&s=0&c=20201002) . We conclude that
. We conclude that![\displaystyle \sigma^{\lfloor n/2 \rfloor - i}[\varphi_{i,j}(w)] \subset [v] \subset K_2^c.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csigma%5E%7B%5Clfloor+n%2F2+%5Crfloor+-+i%7D%5B%5Cvarphi_%7Bi%2Cj%7D%28w%29%5D+%5Csubset+%5Bv%5D+%5Csubset+K_2%5Ec.+&bg=ffffff&fg=000000&s=0&c=20201002)
![{\sigma^{\lfloor n/2 \rfloor - i}[\varphi_{i,j}({\mathcal U}_n)] \subset X \setminus K_2}](https://s0.wp.com/latex.php?latex=%7B%5Csigma%5E%7B%5Clfloor+n%2F2+%5Crfloor+-+i%7D%5B%5Cvarphi_%7Bi%2Cj%7D%28%7B%5Cmathcal+U%7D_n%29%5D+%5Csubset+X+%5Csetminus+K_2%7D&bg=ffffff&fg=000000&s=0&c=20201002) , and now invariance of
, and now invariance of 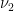 gives
gives![\displaystyle \nu_2([\varphi_{i,j}{\mathcal U}_n]) \leq \nu_2(\sigma^{-(\lfloor n/2 \rfloor - i)}(X\setminus K_2)) = \nu_2(X\setminus K_2) \leq \beta,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cnu_2%28%5B%5Cvarphi_%7Bi%2Cj%7D%7B%5Cmathcal+U%7D_n%5D%29+%5Cleq+%5Cnu_2%28%5Csigma%5E%7B-%28%5Clfloor+n%2F2+%5Crfloor+-+i%29%7D%28X%5Csetminus+K_2%29%29+%3D+%5Cnu_2%28X%5Csetminus+K_2%29+%5Cleq+%5Cbeta%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
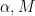 are given by Lemma
are given by Lemma 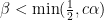 , and apply Lemma
, and apply Lemma 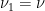 and
and 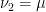 to get
to get  and
and  such that
such that ![{\nu([{\mathcal U}_n]) \geq 1-\beta}](https://s0.wp.com/latex.php?latex=%7B%5Cnu%28%5B%7B%5Cmathcal+U%7D_n%5D%29+%5Cgeq+1-%5Cbeta%7D&bg=ffffff&fg=000000&s=0&c=20201002) for all
for all ![\displaystyle \mu([\varphi_{i,j} {\mathcal U}_n]) \leq \beta \ \ \ \ \ (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmu%28%5B%5Cvarphi_%7Bi%2Cj%7D+%7B%5Cmathcal+U%7D_n%5D%29+%5Cleq+%5Cbeta+%5C+%5C+%5C+%5C+%5C+%284%29&bg=ffffff&fg=000000&s=0&c=20201002)
 , we have
, we have ![{\nu([{\mathcal U}_n]) > \frac 12}](https://s0.wp.com/latex.php?latex=%7B%5Cnu%28%5B%7B%5Cmathcal+U%7D_n%5D%29+%3E+%5Cfrac+12%7D&bg=ffffff&fg=000000&s=0&c=20201002) for all
for all 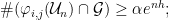
![\displaystyle \mu([\varphi_{i,j} ({\mathcal U}_n) \cap {\mathcal G}]) \geq c e^{-(n-(i+j)) h} \#(\varphi_{i,j}({\mathcal U}_n) \cap {\mathcal G}) \geq c e^{(i+j) h} \alpha \geq c\alpha.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmu%28%5B%5Cvarphi_%7Bi%2Cj%7D+%28%7B%5Cmathcal+U%7D_n%29+%5Ccap+%7B%5Cmathcal+G%7D%5D%29+%5Cgeq+c+e%5E%7B-%28n-%28i%2Bj%29%29+h%7D+%5C%23%28%5Cvarphi_%7Bi%2Cj%7D%28%7B%5Cmathcal+U%7D_n%29+%5Ccap+%7B%5Cmathcal+G%7D%29+%5Cgeq+c+e%5E%7B%28i%2Bj%29+h%7D+%5Calpha+%5Cgeq+c%5Calpha.+&bg=ffffff&fg=000000&s=0&c=20201002)
 and this choice of
and this choice of  , we also have
, we also have ![\displaystyle \beta \geq \mu([\varphi_{i,j} {\mathcal U}_n]) \geq \mu([\varphi_{i,j} ({\mathcal U}_n) \cap {\mathcal G}]) \geq c\alpha.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbeta+%5Cgeq+%5Cmu%28%5B%5Cvarphi_%7Bi%2Cj%7D+%7B%5Cmathcal+U%7D_n%5D%29+%5Cgeq+%5Cmu%28%5B%5Cvarphi_%7Bi%2Cj%7D+%28%7B%5Cmathcal+U%7D_n%29+%5Ccap+%7B%5Cmathcal+G%7D%5D%29+%5Cgeq+c%5Calpha.+&bg=ffffff&fg=000000&s=0&c=20201002)
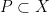 is invariant and
is invariant and 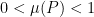 . Let
. Let  be the normalizations of
be the normalizations of  and
and 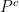 , respectively. Fix
, respectively. Fix  , and apply Lemma
, and apply Lemma 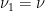 and
and 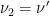 , and once with the roles reversed — to obtain
, and once with the roles reversed — to obtain  and
and 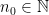 such that
such that ![{\nu'([{\mathcal U}'_n]) \geq 1-\beta}](https://s0.wp.com/latex.php?latex=%7B%5Cnu%27%28%5B%7B%5Cmathcal+U%7D%27_n%5D%29+%5Cgeq+1-%5Cbeta%7D&bg=ffffff&fg=000000&s=0&c=20201002) for every
for every ![\displaystyle \nu([\varphi_{i,j}{\mathcal U}_n']) \leq \beta \text{ and } \nu'([\varphi_{i,j}{\mathcal U}_n]) \leq \beta \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cnu%28%5B%5Cvarphi_%7Bi%2Cj%7D%7B%5Cmathcal+U%7D_n%27%5D%29+%5Cleq+%5Cbeta+%5Ctext%7B+and+%7D+%5Cnu%27%28%5B%5Cvarphi_%7Bi%2Cj%7D%7B%5Cmathcal+U%7D_n%5D%29+%5Cleq+%5Cbeta+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
 , obtaining
, obtaining  (depending on
(depending on 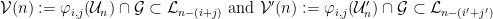
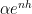 .
.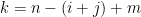 , so that
, so that  for every
for every  . Given any such
. Given any such  , the “two-step” Gibbs property in
, the “two-step” Gibbs property in ![\displaystyle \mu([v] \cap \sigma^{-k}[v']) \geq c e^{-(|v| + |v'|)h} \geq c e^{-2nh}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmu%28%5Bv%5D+%5Ccap+%5Csigma%5E%7B-k%7D%5Bv%27%5D%29+%5Cgeq+c+e%5E%7B-%28%7Cv%7C+%2B+%7Cv%27%7C%29h%7D+%5Cgeq+c+e%5E%7B-2nh%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
 gives
gives ![\displaystyle \mu([{\mathcal V}(n)] \cap \sigma^{-k} [{\mathcal V}'(n)]) \geq c e^{-2nh} (\#{\mathcal V}(n)) (\#{\mathcal V}'(n)) \geq c \alpha^2. \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmu%28%5B%7B%5Cmathcal+V%7D%28n%29%5D+%5Ccap+%5Csigma%5E%7B-k%7D+%5B%7B%5Cmathcal+V%7D%27%28n%29%5D%29+%5Cgeq+c+e%5E%7B-2nh%7D+%28%5C%23%7B%5Cmathcal+V%7D%28n%29%29+%28%5C%23%7B%5Cmathcal+V%7D%27%28n%29%29+%5Cgeq+c+%5Calpha%5E2.+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=0&c=20201002)
![{x\in [{\mathcal V}(n)] \cap \sigma^{-k}[{\mathcal V}'(n)]}](https://s0.wp.com/latex.php?latex=%7Bx%5Cin+%5B%7B%5Cmathcal+V%7D%28n%29%5D+%5Ccap+%5Csigma%5E%7B-k%7D%5B%7B%5Cmathcal+V%7D%27%28n%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , we either have
, we either have  or
or 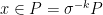 (since
(since ![\displaystyle [{\mathcal V}(n)] \cap \sigma^{-k}[{\mathcal V}'(n)] \subset ([{\mathcal V}(n)] \cap P^c) \cup \sigma^{-k} ([{\mathcal V}'(n)] \cap P).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B%7B%5Cmathcal+V%7D%28n%29%5D+%5Ccap+%5Csigma%5E%7B-k%7D%5B%7B%5Cmathcal+V%7D%27%28n%29%5D+%5Csubset+%28%5B%7B%5Cmathcal+V%7D%28n%29%5D+%5Ccap+P%5Ec%29+%5Ccup+%5Csigma%5E%7B-k%7D+%28%5B%7B%5Cmathcal+V%7D%27%28n%29%5D+%5Ccap+P%29.+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mu([{\mathcal V}(n)] \cap P^c) = \nu'([{\mathcal V}(n)]) \mu(P^c) \leq \nu'([\varphi_{i,j}({\mathcal U}_n)]) \leq \beta](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmu%28%5B%7B%5Cmathcal+V%7D%28n%29%5D+%5Ccap+P%5Ec%29+%3D+%5Cnu%27%28%5B%7B%5Cmathcal+V%7D%28n%29%5D%29+%5Cmu%28P%5Ec%29+%5Cleq+%5Cnu%27%28%5B%5Cvarphi_%7Bi%2Cj%7D%28%7B%5Cmathcal+U%7D_n%29%5D%29+%5Cleq+%5Cbeta+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mu(\sigma^{-k}([{\mathcal V}'(n)] \cap P)) = \mu([{\mathcal V}'(n)] \cap P) \leq \beta,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmu%28%5Csigma%5E%7B-k%7D%28%5B%7B%5Cmathcal+V%7D%27%28n%29%5D+%5Ccap+P%29%29+%3D+%5Cmu%28%5B%7B%5Cmathcal+V%7D%27%28n%29%5D+%5Ccap+P%29+%5Cleq+%5Cbeta%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mu([{\mathcal V}(n)] \cap \sigma^{-k}[{\mathcal V}'(n)]) \leq 2\beta.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmu%28%5B%7B%5Cmathcal+V%7D%28n%29%5D+%5Ccap+%5Csigma%5E%7B-k%7D%5B%7B%5Cmathcal+V%7D%27%28n%29%5D%29+%5Cleq+2%5Cbeta.+&bg=ffffff&fg=000000&s=0&c=20201002)
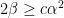 , contradicting our choice of
, contradicting our choice of 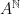 is the set of infinite sequences of symbols from
is the set of infinite sequences of symbols from  , where
, where 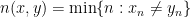 . The shift map
. The shift map 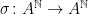 is defined by
is defined by 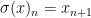 . A shift space is a closed set
. A shift space is a closed set 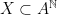 with
with 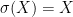 .
. 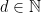 and put
and put  ; then fix a
; then fix a 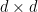 transition matrix
transition matrix  with entries in
with entries in  , and write
, and write 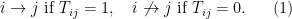
 for all
for all  . This is a topological Markov shift (TMS). It can be viewed in terms of a directed graph with vertex set
. This is a topological Markov shift (TMS). It can be viewed in terms of a directed graph with vertex set 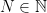 such that
such that 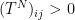 for all
for all 
 of invariant measures is extremely large for a mixing TMS (and more generally for systems with some sort of hyperbolic behavior), and it is important to identify “distinguished” invariant measures. One way of doing this is via the variational principle
of invariant measures is extremely large for a mixing TMS (and more generally for systems with some sort of hyperbolic behavior), and it is important to identify “distinguished” invariant measures. One way of doing this is via the variational principle 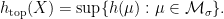
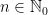 and
and ![{[w] = wX \cap X}](https://s0.wp.com/latex.php?latex=%7B%5Bw%5D+%3D+wX+%5Ccap+X%7D&bg=ffffff&fg=000000&s=0&c=20201002) be the set of sequences in
be the set of sequences in ![\displaystyle \mathcal{L}_n = \{ w\in A^n : [w] \neq \emptyset \}, \qquad \mathcal{L} = \bigcup_{n\in {\mathbb N}_0} \mathcal{L}_n.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathcal%7BL%7D_n+%3D+%5C%7B+w%5Cin+A%5En+%3A+%5Bw%5D+%5Cneq+%5Cemptyset+%5C%7D%2C+%5Cqquad+%5Cmathcal%7BL%7D+%3D+%5Cbigcup_%7Bn%5Cin+%7B%5Cmathbb+N%7D_0%7D+%5Cmathcal%7BL%7D_n.+&bg=ffffff&fg=000000&s=0&c=20201002)
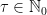 such that for all
such that for all 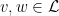 there is
there is 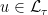 such that
such that  .
. 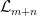 is of the form
is of the form 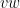 for some
for some  and
and  ; thus
; thus 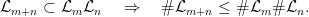
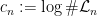 has the sub-additivity property
has the sub-additivity property 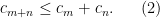
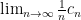 exists and is equal to
exists and is equal to 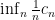 (a priori it could be
(a priori it could be  ).
).  exists for every shift space. This quantifies the growth rate of the total complexity of the system.
exists for every shift space. This quantifies the growth rate of the total complexity of the system.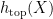 is the box dimension of
is the box dimension of 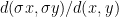 is globally constant whenever
is globally constant whenever ![{p\in (0,1]}](https://s0.wp.com/latex.php?latex=%7Bp%5Cin+%280%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , let
, let 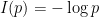 . This can be interpreted as the information associated to an event with probability
. This can be interpreted as the information associated to an event with probability 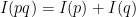 .
. on
on  (and
(and 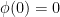 ); this can be interpreted as the expected amount of information associated to an event with probability
); this can be interpreted as the expected amount of information associated to an event with probability 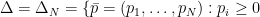 and
and 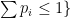 be the set of sub-probability vectors with
be the set of sub-probability vectors with  components. Define
components. Define 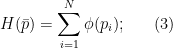
 .
.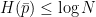 for all
for all  , with equality if and only if
, with equality if and only if 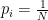 for all
for all 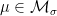 , we have for each
, we have for each 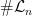 components; writing
components; writing ![{\mu(w) = \mu([w])}](https://s0.wp.com/latex.php?latex=%7B%5Cmu%28w%29+%3D+%5Cmu%28%5Bw%5D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) for convenience, the entropy (expected information) associated to this vector is
for convenience, the entropy (expected information) associated to this vector is 


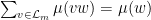 .
.  symbols is at most the expected information from the first
symbols is at most the expected information from the first 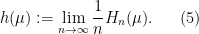
 , with equality if and only if
, with equality if and only if  for all
for all 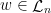 . This immediately proves that
. This immediately proves that 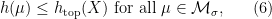

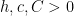 such that for all
such that for all  .
.  and
and 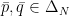 and
and ![{s,t \in [0,1]}](https://s0.wp.com/latex.php?latex=%7Bs%2Ct+%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) with
with 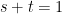 , we have
, we have 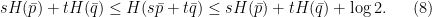
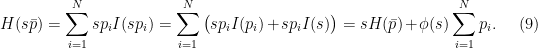

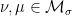 , we see that
, we see that 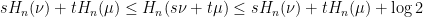
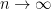 gives
gives 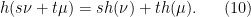
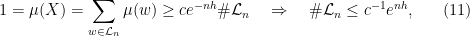
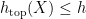 . Meanwhile, the upper Gibbs bound gives
. Meanwhile, the upper Gibbs bound gives 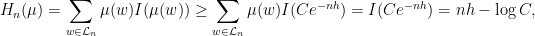
 , so we conclude that
, so we conclude that  . It remains to show that every
. It remains to show that every  with
with  has
has 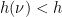 .
. for some
for some 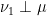 and
and 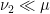 , and
, and 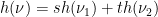 . By ergodicity we must have
. By ergodicity we must have 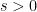 , so if
, so if 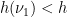 then the same is true of
then the same is true of 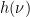 .
.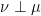 . Then there is a Borel set
. Then there is a Borel set  with
with 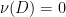 and
and 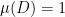 , and this in turn gives
, and this in turn gives  such that
such that 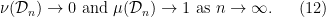
 denote the normalization of
denote the normalization of  , and similarly for
, and similarly for  . Recall from Fekete’s lemma and subadditivity of
. Recall from Fekete’s lemma and subadditivity of 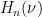 that
that  for all
for all 
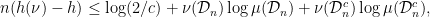
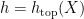 for convenience. Fekete’s lemma gives
for convenience. Fekete’s lemma gives 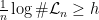 for all
for all 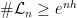 . This can also be deduced by writing
. This can also be deduced by writing 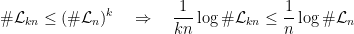
 so that the left-hand side goes to
so that the left-hand side goes to  (this is basically part of the proof of Fekete’s lemma).
(this is basically part of the proof of Fekete’s lemma).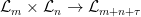 , so that
, so that 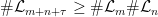 . Then one can either apply Fekete’s lemma to
. Then one can either apply Fekete’s lemma to 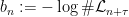 , or observe that
, or observe that 
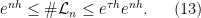
 be any sequence of (not necessarily invariant) Borel probability measures such that
be any sequence of (not necessarily invariant) Borel probability measures such that 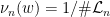 for all
for all 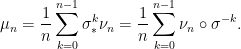
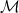 is weak* compact, there is a weak* convergent subsequence
is weak* compact, there is a weak* convergent subsequence  .
. is
is  -invariant (
-invariant ( ).
). 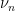 beyond the fact that they are Borel probability measures.
beyond the fact that they are Borel probability measures. and any
and any  , we bound
, we bound ![{\nu_n(\sigma^{-k}[w])}](https://s0.wp.com/latex.php?latex=%7B%5Cnu_n%28%5Csigma%5E%7B-k%7D%5Bw%5D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) by estimating how many words in
by estimating how many words in  for some
for some  and
and  . Arguments similar to those in the uniform counting bounds show that
. Arguments similar to those in the uniform counting bounds show that 
![\displaystyle \nu_n(\sigma^{-k}[w]) \leq \frac{\#\mathcal{L}_k \#\mathcal{L}_{n-k-m}}{\#\mathcal{L}_n} \leq \frac{e^{\tau h} e^{k h} e^{\tau h} e^{(n-k-m)h}}{e^{nh}} = e^{2\tau h} e^{-mh};](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cnu_n%28%5Csigma%5E%7B-k%7D%5Bw%5D%29+%5Cleq+%5Cfrac%7B%5C%23%5Cmathcal%7BL%7D_k+%5C%23%5Cmathcal%7BL%7D_%7Bn-k-m%7D%7D%7B%5C%23%5Cmathcal%7BL%7D_n%7D+%5Cleq+%5Cfrac%7Be%5E%7B%5Ctau+h%7D+e%5E%7Bk+h%7D+e%5E%7B%5Ctau+h%7D+e%5E%7B%28n-k-m%29h%7D%7D%7Be%5E%7Bnh%7D%7D+%3D+e%5E%7B2%5Ctau+h%7D+e%5E%7B-mh%7D%3B+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle e^{-3\tau h} e^{-mh} \leq \nu_n(\sigma^{-k}[w]) \leq e^{2\tau h} e^{-mh}. \ \ \ \ \ (14)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++e%5E%7B-3%5Ctau+h%7D+e%5E%7B-mh%7D+%5Cleq+%5Cnu_n%28%5Csigma%5E%7B-k%7D%5Bw%5D%29+%5Cleq+e%5E%7B2%5Ctau+h%7D+e%5E%7B-mh%7D.+%5C+%5C+%5C+%5C+%5C+%2814%29&bg=ffffff&fg=000000&s=0&c=20201002)
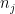 gives
gives 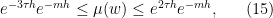
 and
and 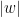 , respectively. Given
, respectively. Given 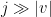 and
and  , follow the same procedure as above to estimate the number of words in
, follow the same procedure as above to estimate the number of words in  with the form
with the form 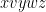 , where
, where  ,
, 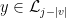 , and
, and 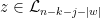 , and obtain the bounds
, and obtain the bounds ![\displaystyle \frac{\#\mathcal{L}_{k-\tau} \#\mathcal{L}_{j-|v|-\tau} \#\mathcal{L}_{n - k - j - |w| - \tau}}{\#\mathcal{L}_n} \leq \sigma_*^k \nu_n([v] \cap \sigma^{-j} [w]) \leq \frac{\#\mathcal{L}_k \#\mathcal{L}_{j-|v|} \#\mathcal{L}_{n - k - j - |w|}}{ \#\mathcal{L}_n}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cfrac%7B%5C%23%5Cmathcal%7BL%7D_%7Bk-%5Ctau%7D+%5C%23%5Cmathcal%7BL%7D_%7Bj-%7Cv%7C-%5Ctau%7D+%5C%23%5Cmathcal%7BL%7D_%7Bn+-+k+-+j+-+%7Cw%7C+-+%5Ctau%7D%7D%7B%5C%23%5Cmathcal%7BL%7D_n%7D+%5Cleq+%5Csigma_%2A%5Ek+%5Cnu_n%28%5Bv%5D+%5Ccap+%5Csigma%5E%7B-j%7D+%5Bw%5D%29+%5Cleq+%5Cfrac%7B%5C%23%5Cmathcal%7BL%7D_k+%5C%23%5Cmathcal%7BL%7D_%7Bj-%7Cv%7C%7D+%5C%23%5Cmathcal%7BL%7D_%7Bn+-+k+-+j+-+%7Cw%7C%7D%7D%7B+%5C%23%5Cmathcal%7BL%7D_n%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle e^{-4\tau h} e^{-|v|h} e^{-|w|h} \leq \mu([v] \cap \sigma^{-j}[w]) \leq e^{3\tau h} e^{-|v|h} e^{-|w|h}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++e%5E%7B-4%5Ctau+h%7D+e%5E%7B-%7Cv%7Ch%7D+e%5E%7B-%7Cw%7Ch%7D+%5Cleq+%5Cmu%28%5Bv%5D+%5Ccap+%5Csigma%5E%7B-j%7D%5Bw%5D%29+%5Cleq+e%5E%7B3%5Ctau+h%7D+e%5E%7B-%7Cv%7Ch%7D+e%5E%7B-%7Cw%7Ch%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle e^{-8\tau h} \mu(v) \mu(w) \leq \mu([v] \cap \sigma^{-j}[w]) \leq e^{9\tau h} \mu(v) \mu(w). \ \ \ \ \ (16)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++e%5E%7B-8%5Ctau+h%7D+%5Cmu%28v%29+%5Cmu%28w%29+%5Cleq+%5Cmu%28%5Bv%5D+%5Ccap+%5Csigma%5E%7B-j%7D%5Bw%5D%29+%5Cleq+e%5E%7B9%5Ctau+h%7D+%5Cmu%28v%29+%5Cmu%28w%29.+%5C+%5C+%5C+%5C+%5C+%2816%29&bg=ffffff&fg=000000&s=0&c=20201002)
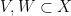 , approximate
, approximate  and
and  with cylinders and use
with cylinders and use 
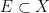 is invariant, then taking
is invariant, then taking 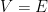 and
and 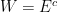 in Exercise
in Exercise  , so
, so 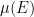 is either
is either 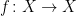 (typically
(typically  in one of the following two roles.
in one of the following two roles.  represents measurements made at different times, about which we want to make predictions. In the cases we are interested in, these predictions will be probabilistic and will be in terms of the Birkhoff averages
represents measurements made at different times, about which we want to make predictions. In the cases we are interested in, these predictions will be probabilistic and will be in terms of the Birkhoff averages  , where
, where 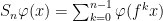 is the
is the 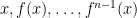 is assigned a weight given by
is assigned a weight given by 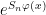 . A potential function also assigns weights to invariant measures by integration; in particular, we can study equilibrium measures for
. A potential function also assigns weights to invariant measures by integration; in particular, we can study equilibrium measures for  , which are invariant probability measures maximizing
, which are invariant probability measures maximizing  is Kolmogorov–Sinai entropy.)
is Kolmogorov–Sinai entropy.)
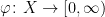 can also play the role of a density function, especially if we are looking for an invariant measure that is absolutely continuous with respect to some reference measure, but for today we will focus on the two roles described above.
can also play the role of a density function, especially if we are looking for an invariant measure that is absolutely continuous with respect to some reference measure, but for today we will focus on the two roles described above.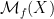 denote the set of
denote the set of 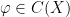 induces a map
induces a map 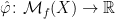 by
by 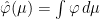 as in the second item above. It is natural to ask when two functions
as in the second item above. It is natural to ask when two functions 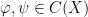 have
have 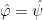 . One immediate observation to make is that the defintion of
. One immediate observation to make is that the defintion of 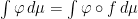 for all
for all 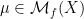 , so that in particular we have
, so that in particular we have 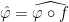 . Thus the function
. Thus the function 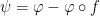 has
has  . We call such a function
. We call such a function  for every
for every 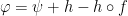 for some
for some  , which we call the transfer function. Note that
, which we call the transfer function. Note that 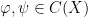 can have
can have  there exists
there exists  and
and 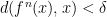 , then there exists
, then there exists 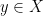 such that
such that 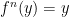 and
and  for all
for all  .
. 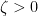 there exist
there exist  for all
for all  .
.  , we have
, we have  .
. 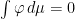 for every invariant
for every invariant 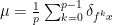 . Equivalently one can observe that Birkhoff sums of coboundaries have the following behavior: if
. Equivalently one can observe that Birkhoff sums of coboundaries have the following behavior: if 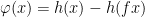 , then
, then 
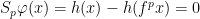 whenever
whenever 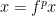 . We must prove the reverse implication, that if
. We must prove the reverse implication, that if  whenever
whenever 
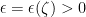 be given by the Walters Property, and then let
be given by the Walters Property, and then let  be given by the Closing Lemma. Suppose that
be given by the Closing Lemma. Suppose that 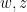 are two points on the orbit of
are two points on the orbit of 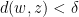 . Since
. Since 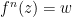 or
or 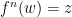 . Without loss of generality we assume the first case, so that
. Without loss of generality we assume the first case, so that  . By the Closing Lemma there is a periodic point
. By the Closing Lemma there is a periodic point 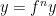 such that
such that  for all
for all 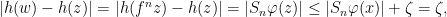
 to verify that this relationship continues to hold on all of
to verify that this relationship continues to hold on all of  be as in the Livsic Theorem; then for any
be as in the Livsic Theorem; then for any 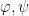 satisfying the Walters Property, the following are equivalent:
satisfying the Walters Property, the following are equivalent: 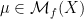 ;
;
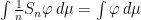 for every
for every 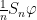 is cohomologous to
is cohomologous to 
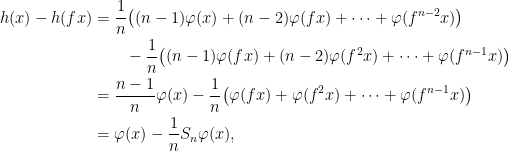
 , the interval map
, the interval map ![{T\colon [0,1]\rightarrow [0,1]}](https://s0.wp.com/latex.php?latex=%7BT%5Ccolon+%5B0%2C1%5D%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) given by
given by  is naturally semi-conjugate to the
is naturally semi-conjugate to the 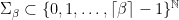 . The shift space
. The shift space 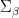 admits a natural description in terms of the lexicographic order, and another in terms of a countable-state directed graph. These have been used to obtain a fairly complete description of the dynamics of the
admits a natural description in terms of the lexicographic order, and another in terms of a countable-state directed graph. These have been used to obtain a fairly complete description of the dynamics of the 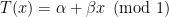 . Just as with the
. Just as with the  and a partition of
and a partition of 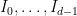 such that
such that 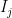 and
and 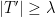 . Note that we do not care whether the intervals are closed, open, or half of each.
. Note that we do not care whether the intervals are closed, open, or half of each.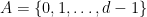 , and define a map
, and define a map ![{h\colon [0,1]\rightarrow A^{\mathbb N}}](https://s0.wp.com/latex.php?latex=%7Bh%5Ccolon+%5B0%2C1%5D%5Crightarrow+A%5E%7B%5Cmathbb+N%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) by
by  whenever
whenever  . Let
. Let ![{\Sigma = \Sigma_T = \overline{h([0,1])}}](https://s0.wp.com/latex.php?latex=%7B%5CSigma+%3D+%5CSigma_T+%3D+%5Coverline%7Bh%28%5B0%2C1%5D%29%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) ; we say that
; we say that  is the coding space for the interval map
is the coding space for the interval map 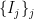 . We can define a map
. We can define a map ![{\pi\colon \Sigma\rightarrow [0,1]}](https://s0.wp.com/latex.php?latex=%7B%5Cpi%5Ccolon+%5CSigma%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) by the condition that
by the condition that  for all
for all ![{x\in [0,1]}](https://s0.wp.com/latex.php?latex=%7Bx%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and
and  is continuous. Then we have
is continuous. Then we have  , so
, so 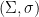 and
and ![{([0,1],T)}](https://s0.wp.com/latex.php?latex=%7B%28%5B0%2C1%5D%2CT%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
. such that
such that  for all
for all 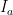 . Note that
. Note that  is
is 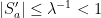 . Given any set
. Given any set ![{E\subset [0,1]}](https://s0.wp.com/latex.php?latex=%7BE%5Csubset+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , write
, write 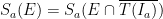 for convenience; note that
for convenience; note that 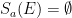 if
if  . Given a finite word
. Given a finite word ![{J_w = S_w([0,1])}](https://s0.wp.com/latex.php?latex=%7BJ_w+%3D+S_w%28%5B0%2C1%5D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) , where
, where  and
and 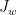 represents the set of points
represents the set of points  ,
,  , and so on. (This is not quite completely true because of problems at the endpoints of the intervals.)
, and so on. (This is not quite completely true because of problems at the endpoints of the intervals.) 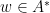 such that
such that ![{[w] := \{x\in \Sigma : x_1 \cdots x_{|w|} = w\} \neq\emptyset}](https://s0.wp.com/latex.php?latex=%7B%5Bw%5D+%3A%3D+%5C%7Bx%5Cin+%5CSigma+%3A+x_1+%5Ccdots+x_%7B%7Cw%7C%7D+%3D+w%5C%7D+%5Cneq%5Cemptyset%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Write
. Write 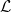 for this collection of words; then
for this collection of words; then 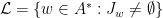 , and we have
, and we have ![{\pi([w]) = J_w}](https://s0.wp.com/latex.php?latex=%7B%5Cpi%28%5Bw%5D%29+%3D+J_w%7D&bg=ffffff&fg=000000&s=0&c=20201002) for all
for all 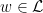 . Let
. Let 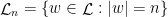 ; given
; given 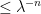 , and since for every
, and since for every  we have
we have ![{\{x\} = \bigcap_{n\geq 0} [x_1\cdots x_n]}](https://s0.wp.com/latex.php?latex=%7B%5C%7Bx%5C%7D+%3D+%5Cbigcap_%7Bn%5Cgeq+0%7D+%5Bx_1%5Ccdots+x_n%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , we also have
, we also have 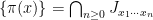 .
.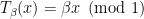 and
and  , where
, where 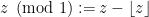 and we assume without loss of generality that
and we assume without loss of generality that 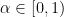 . These are piecewise expanding interval maps, where the natural partition to consider is the partition into maximal intervals of continuity. Thus for
. These are piecewise expanding interval maps, where the natural partition to consider is the partition into maximal intervals of continuity. Thus for 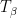 , we have
, we have 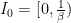 ,
,  , and so on, with
, and so on, with ![{I_{d-1} = [\frac {d-1}\beta,1]}](https://s0.wp.com/latex.php?latex=%7BI_%7Bd-1%7D+%3D+%5B%5Cfrac+%7Bd-1%7D%5Cbeta%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , where
, where 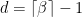 . For
. For  , we have
, we have  ,
,  , and so on, with
, and so on, with  and
and ![{I_{d-1} = [\frac{d-1+\alpha}{\beta},1]}](https://s0.wp.com/latex.php?latex=%7BI_%7Bd-1%7D+%3D+%5B%5Cfrac%7Bd-1%2B%5Calpha%7D%7B%5Cbeta%7D%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . We write
. We write  for the coding spaces of these transformations relative to their natural partitions.
for the coding spaces of these transformations relative to their natural partitions.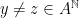 , let
, let 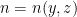 be minimal such that
be minimal such that 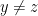 , and write
, and write 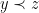 if
if 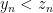 . Write
. Write  if
if  . This is a total order on
. This is a total order on 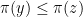 if and only if
if and only if 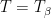 . Let
. Let 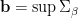 , where supremum is w.r.t. lexicographic order; the supremum exists because
, where supremum is w.r.t. lexicographic order; the supremum exists because 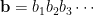 is the lexicographically maximal element of
is the lexicographically maximal element of 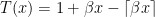 , which agrees with
, which agrees with ![{T^n(1) \in [0,1]}](https://s0.wp.com/latex.php?latex=%7BT%5En%281%29+%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) will play an important role in the following result.
will play an important role in the following result.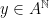 is in
is in 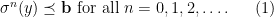
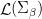 if and only if
if and only if 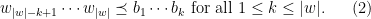
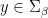 satisfies
satisfies  satisfies
satisfies 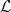 ; in other words, that
; in other words, that 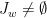 for every such
for every such 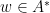 the follower interval
the follower interval 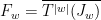 ; this can also be defined as the minimal interval with the property that
; this can also be defined as the minimal interval with the property that ![{S_w([0,1]\setminus F_w)=\emptyset}](https://s0.wp.com/latex.php?latex=%7BS_w%28%5B0%2C1%5D%5Csetminus+F_w%29%3D%5Cemptyset%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Note that
. Note that 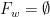 whenever
whenever  . Given
. Given 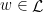 and
and ![\displaystyle F_{wa} = \overline{T^{1+|w|}(J_{wa})} = \overline{T(T^{|w|}S_w S_a[0,1])} = \overline{T(T^{|w|}S_w I_a)} = \overline{T(F_w \cap I_a)}. \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++F_%7Bwa%7D+%3D+%5Coverline%7BT%5E%7B1%2B%7Cw%7C%7D%28J_%7Bwa%7D%29%7D+%3D+%5Coverline%7BT%28T%5E%7B%7Cw%7C%7DS_w+S_a%5B0%2C1%5D%29%7D+%3D+%5Coverline%7BT%28T%5E%7B%7Cw%7C%7DS_w+I_a%29%7D+%3D+%5Coverline%7BT%28F_w+%5Ccap+I_a%29%7D.+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002)
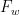 that completes the proof of Proposition
that completes the proof of Proposition 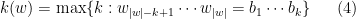
 that appears as a suffix of
that appears as a suffix of ![{F_w = [0,T^{k(w)}(1)]}](https://s0.wp.com/latex.php?latex=%7BF_w+%3D+%5B0%2CT%5E%7Bk%28w%29%7D%281%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
. 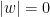 (so
(so ![{F_w = [0,1]}](https://s0.wp.com/latex.php?latex=%7BF_w+%3D+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) ) as the base case. Suppose we have some
) as the base case. Suppose we have some 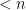 . Write
. Write 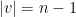 and
and 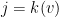 , so that
, so that 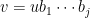 for some word
for some word ![{F_v = [0,T^{j}(1)]}](https://s0.wp.com/latex.php?latex=%7BF_v+%3D+%5B0%2CT%5E%7Bj%7D%281%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and hence
and hence 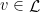 . Then by
. Then by ![\displaystyle F_w = F_{va} = \overline{T(F_v \cap I_a)} = \overline{T([0,T^{k(v)}(1)] \cap I_a)}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++F_w+%3D+F_%7Bva%7D+%3D+%5Coverline%7BT%28F_v+%5Ccap+I_a%29%7D+%3D+%5Coverline%7BT%28%5B0%2CT%5E%7Bk%28v%29%7D%281%29%5D+%5Ccap+I_a%29%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
 . In this case we have
. In this case we have  and
and  , and
, and ![{F_w = \overline{T([\frac a\beta,T^{k(v)}(1)])} = [0,T^{k(v)+1}] = [0,T^{k(w)}(1)]}](https://s0.wp.com/latex.php?latex=%7BF_w+%3D+%5Coverline%7BT%28%5B%5Cfrac+a%5Cbeta%2CT%5E%7Bk%28v%29%7D%281%29%5D%29%7D+%3D+%5B0%2CT%5E%7Bk%28v%29%2B1%7D%5D+%3D+%5B0%2CT%5E%7Bk%28w%29%7D%281%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
. . In this case we must have
. In this case we must have  , otherwise we would have
, otherwise we would have 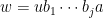 and hence
and hence 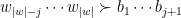 , violating
, violating  and hence by
and hence by ![{F_w = \overline{T(I_a)} = [0,1]}](https://s0.wp.com/latex.php?latex=%7BF_w+%3D+%5Coverline%7BT%28I_a%29%7D+%3D+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . On the other hand, since
. On the other hand, since  we have
we have 
 . We conclude that
. We conclude that  , which completes the proof of Lemma
, which completes the proof of Lemma  implies that
implies that  and
and 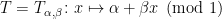 , and let
, and let  be the coding space for
be the coding space for  and
and 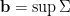 be the lexicographically minimal and maximal elements of
be the lexicographically minimal and maximal elements of 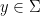 has the property that
has the property that 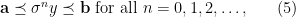
 has the property that
has the property that 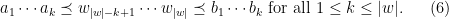
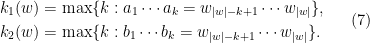
![{F_w = [\underline{T}^{k_1(w)}(0),\overline{T}^{k_2(w)}(1)]}](https://s0.wp.com/latex.php?latex=%7BF_w+%3D+%5B%5Cunderline%7BT%7D%5E%7Bk_1%28w%29%7D%280%29%2C%5Coverline%7BT%7D%5E%7Bk_2%28w%29%7D%281%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , where
, where  and
and  agree with
agree with 
![\displaystyle F^w = \{y\in \Sigma : wy\in \Sigma \} = \sigma^{|w|}([w] \cap \Sigma). \ \ \ \ \ (8)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++F%5Ew+%3D+%5C%7By%5Cin+%5CSigma+%3A+wy%5Cin+%5CSigma+%5C%7D+%3D+%5Csigma%5E%7B%7Cw%7C%7D%28%5Bw%5D+%5Ccap+%5CSigma%29.+%5C+%5C+%5C+%5C+%5C+%288%29&bg=ffffff&fg=000000&s=0&c=20201002)
 , but the definition in
, but the definition in  is finite. Such shifts are called sofic. Similarly,
is finite. Such shifts are called sofic. Similarly,  with the property that
with the property that  for all
for all 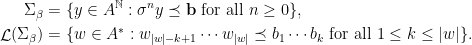
![\displaystyle F^w = \{y\in \Sigma : y\preceq \sigma^{k(w)}{\mathbf b}\} =: [\mathbf{0},\sigma^{k(w)}{\mathbf b}],](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++F%5Ew+%3D+%5C%7By%5Cin+%5CSigma+%3A+y%5Cpreceq+%5Csigma%5E%7Bk%28w%29%7D%7B%5Cmathbf+b%7D%5C%7D+%3D%3A+%5B%5Cmathbf%7B0%7D%2C%5Csigma%5E%7Bk%28w%29%7D%7B%5Cmathbf+b%7D%5D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
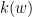 is defined in
is defined in 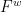 is completely determined by
is completely determined by  for some
for some 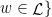 . A labeled edge is a triple
. A labeled edge is a triple 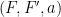 , where
, where 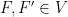 and
and 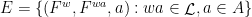 ; that is, there is an edge from
; that is, there is an edge from 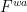 whenever
whenever 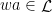 and
and 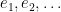 such that for every
such that for every  is labeled with the symbol
is labeled with the symbol 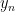 , and
, and
 .
.
 for all
for all 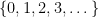 , and observe that the two cases in Lemma
, and observe that the two cases in Lemma  whenever there are
whenever there are  ,
, 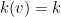 , and
, and 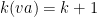 . This happens for every
. This happens for every  and
and  , so the edge from
, so the edge from 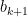 .
.
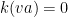 . This happens whenever
. This happens whenever 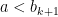 , and so whenever
, and so whenever 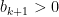 there are
there are 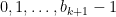 .
.
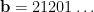 , the first part of the graph looks like this:
, the first part of the graph looks like this: 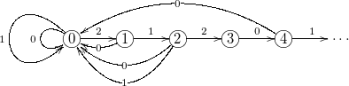
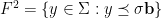 ; a sequence
; a sequence 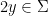 . For a more typical sort of example, let
. For a more typical sort of example, let  . Then
. Then  ), then goes out to vertex 4 before returning to vertex 0 (because
), then goes out to vertex 4 before returning to vertex 0 (because 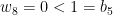 ), then goes out to vertex 3 and stops. We see that
), then goes out to vertex 3 and stops. We see that 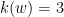 and that
and that 
 with the property that
with the property that 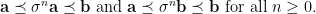
 and
and 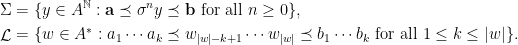
![\displaystyle F^w = [\sigma^{k_1(w)}{\mathbf a},\sigma^{k_2(w)}{\mathbf b}],](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++F%5Ew+%3D+%5B%5Csigma%5E%7Bk_1%28w%29%7D%7B%5Cmathbf+a%7D%2C%5Csigma%5E%7Bk_2%28w%29%7D%7B%5Cmathbf+b%7D%5D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
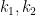 are given by
are given by  and
and  , and so we can represent
, and so we can represent  . As we will see momentarily, not every pair
. As we will see momentarily, not every pair  corresponds to a follower set, so we will not use all such vertices in building the graph, but thinking of the integer lattice still provides a useful way to visualize that situation.
corresponds to a follower set, so we will not use all such vertices in building the graph, but thinking of the integer lattice still provides a useful way to visualize that situation. and
and  . Then some of the follower sets, together with their corresponding values of
. Then some of the follower sets, together with their corresponding values of 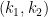 , are as follows:
, are as follows: ![\displaystyle \begin{aligned} \Sigma &= [{\mathbf a},{\mathbf b}] \quad &&(0,0), \qquad\qquad & F^{01} &= [\sigma^2{\mathbf a},{\mathbf b}] \quad &&(2,0), \\ F^0 &= [\sigma{\mathbf a},{\mathbf b}] &&(1,0), & F^{012} &= [\sigma^2{\mathbf a},\sigma {\mathbf b}] &&(3,1), \\ F^1 &= [{\mathbf a},{\mathbf b}] &&(0,0), & F^{0121} &= [\sigma^4{\mathbf a},\sigma^2{\mathbf b}] && (4,2), \\ F^2 &= [{\mathbf a},\sigma{\mathbf b}] &&(0,1), & F^{01210} &= [\sigma^5{\mathbf a},{\mathbf b}] && (5,0). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%5CSigma+%26%3D+%5B%7B%5Cmathbf+a%7D%2C%7B%5Cmathbf+b%7D%5D+%5Cquad+%26%26%280%2C0%29%2C+%5Cqquad%5Cqquad+%26+F%5E%7B01%7D+%26%3D+%5B%5Csigma%5E2%7B%5Cmathbf+a%7D%2C%7B%5Cmathbf+b%7D%5D+%5Cquad+%26%26%282%2C0%29%2C+%5C%5C+F%5E0+%26%3D+%5B%5Csigma%7B%5Cmathbf+a%7D%2C%7B%5Cmathbf+b%7D%5D+%26%26%281%2C0%29%2C+%26+F%5E%7B012%7D+%26%3D+%5B%5Csigma%5E2%7B%5Cmathbf+a%7D%2C%5Csigma+%7B%5Cmathbf+b%7D%5D+%26%26%283%2C1%29%2C+%5C%5C+F%5E1+%26%3D+%5B%7B%5Cmathbf+a%7D%2C%7B%5Cmathbf+b%7D%5D+%26%26%280%2C0%29%2C+%26+F%5E%7B0121%7D+%26%3D+%5B%5Csigma%5E4%7B%5Cmathbf+a%7D%2C%5Csigma%5E2%7B%5Cmathbf+b%7D%5D+%26%26+%284%2C2%29%2C+%5C%5C+F%5E2+%26%3D+%5B%7B%5Cmathbf+a%7D%2C%5Csigma%7B%5Cmathbf+b%7D%5D+%26%26%280%2C1%29%2C+%26+F%5E%7B01210%7D+%26%3D+%5B%5Csigma%5E5%7B%5Cmathbf+a%7D%2C%7B%5Cmathbf+b%7D%5D+%26%26+%285%2C0%29.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
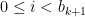 , and from
, and from  , depending on whether
, depending on whether 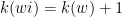 or
or 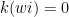 . (We switch to using
. (We switch to using  and
and  :
: 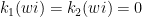 , which happens if
, which happens if 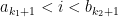 , and gives an edge from
, and gives an edge from  labeled
labeled  and
and  , which happens if
, which happens if  , and gives an edge from
, and gives an edge from  labeled
labeled  and
and 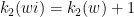 , which happens if
, which happens if  , and gives an edge from
, and gives an edge from 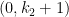 labeled
labeled 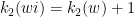 , which happens if
, which happens if 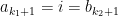 , and gives an edge from
, and gives an edge from  labeled
labeled  instead of
instead of  , and so on, in order to save space.
, and so on, in order to save space. 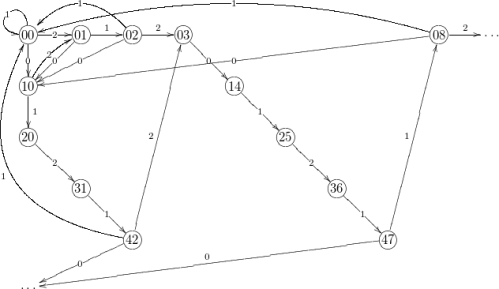
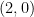 ,
, 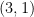 ,
,  , with exactly one outgoing edge, which goes down and to the right; on the other hand there are vertices which have at least two outgoing edges, each of which `resets’ in either the horizontal or vertical directions (or both).
, with exactly one outgoing edge, which goes down and to the right; on the other hand there are vertices which have at least two outgoing edges, each of which `resets’ in either the horizontal or vertical directions (or both).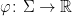 has the property that every equilibrium state for
has the property that every equilibrium state for 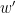 is obtained from
is obtained from 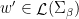 as well. This is no longer true for
as well. This is no longer true for 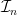 in the proof of the main theorem needed to be modified so that each
in the proof of the main theorem needed to be modified so that each 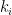 is a multiple of
is a multiple of 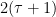 . Thanks to Leonard Carapezza for pointing this out to me.]
. Thanks to Leonard Carapezza for pointing this out to me.] is the value of this maximum.
is the value of this maximum.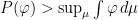 ), but I do not know of an explicit reference. In this post I provide a proof of this fact, which also gives reasonably concrete bounds on the entropy of
), but I do not know of an explicit reference. In this post I provide a proof of this fact, which also gives reasonably concrete bounds on the entropy of 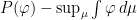 .
.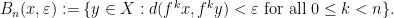
 such that for every
such that for every 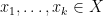 and
and  , there is
, there is 
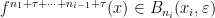
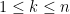 . We refer to
. We refer to  as the “gluing time”; one could also consider a weaker property where the gluing times are allowed to vary but must be bounded above by
as the “gluing time”; one could also consider a weaker property where the gluing times are allowed to vary but must be bounded above by 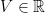 is such that
is such that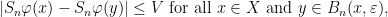
 . We write
. We write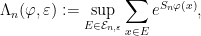
 is the collection of
is the collection of  for which
for which  whenever
whenever 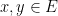 ,
, 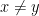 ). The topological pressure is
). The topological pressure is 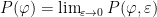 , where
, where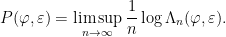
 ,
, 
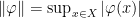 . Then we have
. Then we have 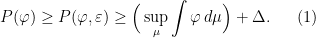
 .
. such that
such that 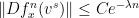 for all
for all  , and similarly for
, and similarly for  and
and  such that
such that 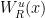 is
is 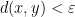 implies that
implies that 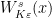 intersects
intersects 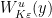 in a unique point
in a unique point  , and the leafwise distances from
, and the leafwise distances from  ;
;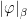 ) for the potential
) for the potential 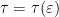 is determined by the condition that
is determined by the condition that  , so that small pieces of unstable manifold expand to become
, so that small pieces of unstable manifold expand to become 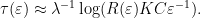
 and
and 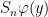 by comparing each to
by comparing each to 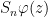 , where
, where 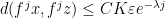 , so the Hölder property gives
, so the Hölder property gives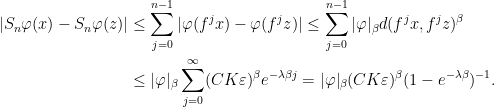
 gives
gives
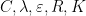 the quantities above. Let
the quantities above. Let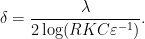
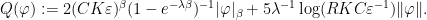

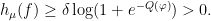
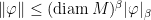 and write the following consequence of the above, which is somewhat simpler in appearance.
and write the following consequence of the above, which is somewhat simpler in appearance. and
and 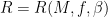 such that for every
such that for every 
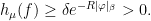
 , this gives an estimate on how large
, this gives an estimate on how large  .
.![{\alpha\in (0,\frac 12]}](https://s0.wp.com/latex.php?latex=%7B%5Calpha%5Cin+%280%2C%5Cfrac+12%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Let
. Let 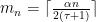 , and let
, and let
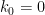 and
and 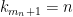 . The idea is that for each
. The idea is that for each 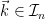 , we will use the specification property to construct a point
, we will use the specification property to construct a point  whose orbit shadows the orbit of
whose orbit shadows the orbit of  will be
will be  from below; this requires a lower bound on
from below; this requires a lower bound on 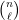 . Integrating
. Integrating 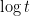 over
over ![{[1,k]}](https://s0.wp.com/latex.php?latex=%7B%5B1%2Ck%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and
and ![{[1,k+1]}](https://s0.wp.com/latex.php?latex=%7B%5B1%2Ck%2B1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) gives
gives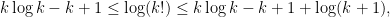
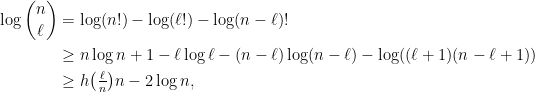
 . This function is increasing on
. This function is increasing on  , so
, so 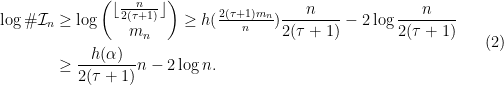
 , let
, let  be any point with
be any point with  (using the assumption on the diameter of
(using the assumption on the diameter of  , the specification property guarantees the existence of a point
, the specification property guarantees the existence of a point 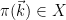 with the property that
with the property that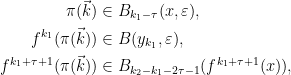
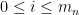 we have
we have 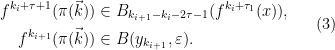
 ; then the first inclusion in
; then the first inclusion in 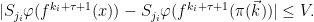


 . The second inclusion in
. The second inclusion in  , we can take
, we can take  , let
, let 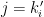 , and then observe that
, and then observe that 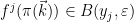 and
and 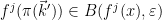 ; since
; since  this guarantees that
this guarantees that  .
.
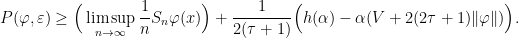
 . Thus to bound the difference
. Thus to bound the difference 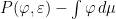 , we want to choose the value of
, we want to choose the value of ![{\alpha \in (0,\frac 12]}](https://s0.wp.com/latex.php?latex=%7B%5Calpha+%5Cin+%280%2C%5Cfrac+12%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) that maximizes
that maximizes  , where
, where 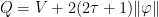 .
.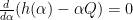 occurs when
occurs when  , at which point we have
, at which point we have 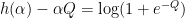 , proving Theorem
, proving Theorem  be a probability space and
be a probability space and  be Banach spaces of measurable functions on
be Banach spaces of measurable functions on  the corresponding norms. Given
the corresponding norms. Given 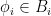 and
and 
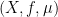 has exponential decay of correlations with respect to observables in
has exponential decay of correlations with respect to observables in 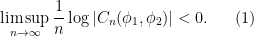
 and
and 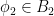 , there are
, there are  and
and 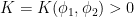 such that
such that 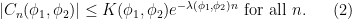
 and
and  , independent of
, independent of  , such that
, such that 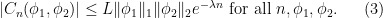
 ; this is the goal of this post, to show that
; this is the goal of this post, to show that  can be chosen uniformly over all
can be chosen uniformly over all  , and that
, and that  can be chosen to have the form
can be chosen to have the form 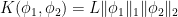 . This seems like the sort of thing which is likely known to experts, but I am not aware of the reference in the literature. (I would be happy to learn a reference!)
. This seems like the sort of thing which is likely known to experts, but I am not aware of the reference in the literature. (I would be happy to learn a reference!)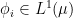 and
and  ;
;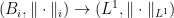 are continuous;
are continuous; given by
given by 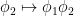 is continuous, and similarly for the map
is continuous, and similarly for the map  when
when 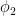 is fixed;
is fixed; given by
given by  is bounded w.r.t.
is bounded w.r.t.  .
.![{K_\lambda^{\phi_1} \colon B_2 \rightarrow [0,\infty]}](https://s0.wp.com/latex.php?latex=%7BK_%5Clambda%5E%7B%5Cphi_1%7D+%5Ccolon+B_2+%5Crightarrow+%5B0%2C%5Cinfty%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) given by
given by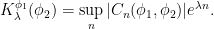
 is bilinear in
is bilinear in  and
and  , we have
, we have 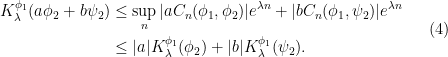
 :
:
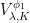 are nested (smaller
are nested (smaller 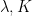 , meaning that we can treat
, meaning that we can treat 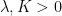 such that the closure of
such that the closure of  such that
such that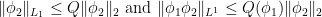
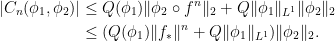
 such that
such that 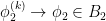 w.r.t.
w.r.t. 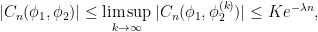
 , so this set is closed. In particular, there is
, so this set is closed. In particular, there is 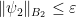 , then
, then 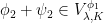 . By the same token
. By the same token 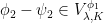 , and now the sublinearity property
, and now the sublinearity property 
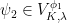 . This shows that
. This shows that 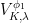 contains a neighbourhood of 0, and writing
contains a neighbourhood of 0, and writing 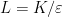 , we see that for every
, we see that for every  we have
we have 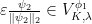 , and so
, and so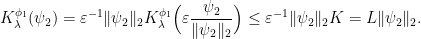
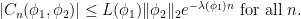

 , and so once again there are
, and so once again there are 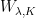 has non-empty interior. Given a sequence
has non-empty interior. Given a sequence 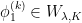 with
with 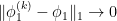 , we have
, we have  for all
for all  , demonstrating that this set is closed.
, demonstrating that this set is closed. implies
implies 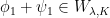 . In particular this gives
. In particular this gives  , and so for every
, and so for every 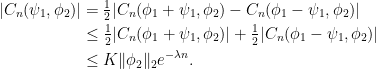
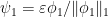 , which has
, which has 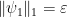 , and so
, and so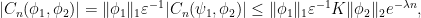
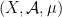 , the
, the 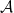 is countably generated mod 0 (which we denoted (CG0)) if and only if the pseudo-metric
is countably generated mod 0 (which we denoted (CG0)) if and only if the pseudo-metric  makes
makes 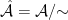 into a separable metric space. We also considered
into a separable metric space. We also considered 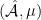 as a measured abstract
as a measured abstract  be a separable measured abstract
be a separable measured abstract 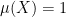 . Note that
. Note that 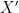 is the minimal element of
is the minimal element of  if
if  for this minimal element.
for this minimal element.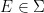 is an atom if it has no proper non-trivial subelement; that is, if
is an atom if it has no proper non-trivial subelement; that is, if 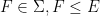 implies
implies  or
or  . By the assumption that
. By the assumption that 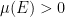 for every atom. Note that for any two atoms
for every atom. Note that for any two atoms  we have
we have  , and so
, and so  .
. be the set of atoms; then we have
be the set of atoms; then we have  , so
, so 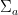 is (at most) countable. Let
is (at most) countable. Let 
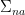 is non-atomic; it contains no atoms. Thus
is non-atomic; it contains no atoms. Thus 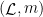 is a measured abstract
is a measured abstract 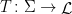 that preserves the Boolean algebra structure and carries
that preserves the Boolean algebra structure and carries  iff
iff 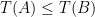 ;
; 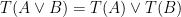 ;
; 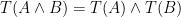 ;
; 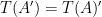 ;
;  ; and finally,
; and finally,  . We are most used to obtaining morphisms between
. We are most used to obtaining morphisms between 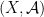 and
and 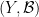 , a measurable map
, a measurable map 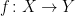 gives a morphism
gives a morphism  . However, in the abstract setting we currently work in, there is no ambient space, so we cannot yet interpret
. However, in the abstract setting we currently work in, there is no ambient space, so we cannot yet interpret  back to the measure spaces that induced them, and then we will give conditions for
back to the measure spaces that induced them, and then we will give conditions for ![{A\subset [0,1]}](https://s0.wp.com/latex.php?latex=%7BA%5Csubset+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , we write
, we write ![{[A]\in \mathop{\mathcal L}}](https://s0.wp.com/latex.php?latex=%7B%5BA%5D%5Cin+%5Cmathop%7B%5Cmathcal+L%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) for the equivalence class of
for the equivalence class of ![{[[a,b]]\in \mathop{\mathcal L}}](https://s0.wp.com/latex.php?latex=%7B%5B%5Ba%2Cb%5D%5D%5Cin+%5Cmathop%7B%5Cmathcal+L%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) for the equivalence class of the interval
for the equivalence class of the interval ![{[a,b]}](https://s0.wp.com/latex.php?latex=%7B%5Ba%2Cb%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.![{Q\subset [0,1]}](https://s0.wp.com/latex.php?latex=%7BQ%5Csubset+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is dense, then
is dense, then ![{\{[0,q]] : q\in Q\}}](https://s0.wp.com/latex.php?latex=%7B%5C%7B%5B0%2Cq%5D%5D+%3A+q%5Cin+Q%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) ; thus we can describe
; thus we can describe 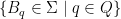 such that
such that ![{\mu(B_q) = q = m[[0,q]]}](https://s0.wp.com/latex.php?latex=%7B%5Cmu%28B_q%29+%3D+q+%3D+m%5B%5B0%2Cq%5D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) ,
,
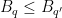 whenever
whenever  ,
,
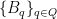 generates
generates ![{T(B_q) = [[0,q]]}](https://s0.wp.com/latex.php?latex=%7BT%28B_q%29+%3D+%5B%5B0%2Cq%5D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . This is where separability comes in. Let
. This is where separability comes in. Let  be a countable collection that generates
be a countable collection that generates ![{T(A_1) = [[0,\mu(A_1)]]}](https://s0.wp.com/latex.php?latex=%7BT%28A_1%29+%3D+%5B%5B0%2C%5Cmu%28A_1%29%5D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , so
, so 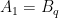 for
for  . Now what about
. Now what about 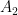 ? We can use
? We can use  by noting that
by noting that 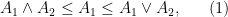
![{T(E) = [[0,\mu(E)]]}](https://s0.wp.com/latex.php?latex=%7BT%28E%29+%3D+%5B%5B0%2C%5Cmu%28E%29%5D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) for
for  .
.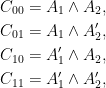
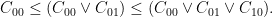
 for the lexicographic order on
for the lexicographic order on  , we observe that each of these three is of the form
, we observe that each of these three is of the form 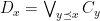 for some
for some 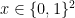 .
. 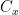 above is determined as follows:
above is determined as follows:  tells us whether to use
tells us whether to use  or
or  , and
, and 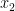 tells us whether to use
tells us whether to use 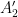 . This generalises very naturally to
. This generalises very naturally to 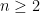 : given
: given 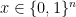 , let
, let 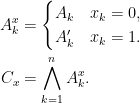
 elements
elements 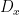 (the last one is
(the last one is 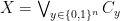 , and was omitted from our earlier bookkeeping). These have the property that
, and was omitted from our earlier bookkeeping). These have the property that 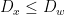 whenever
whenever  . Moreover, writing
. Moreover, writing  , the collection
, the collection  generates
generates  does. Let
does. Let ![{T(D_x) = [[0,\mu(D_x)]]}](https://s0.wp.com/latex.php?latex=%7BT%28D_x%29+%3D+%5B%5B0%2C%5Cmu%28D_x%29%5D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) ; now we have all the pieces of the construction that we asked for earlier.
; now we have all the pieces of the construction that we asked for earlier.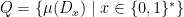 . The following are now relatively straightforward exercises.
. The following are now relatively straightforward exercises.  there is
there is 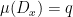 ; if
; if  such that this holds, then either
such that this holds, then either  or
or 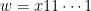 (or vice versa). For this step we actually need to choose
(or vice versa). For this step we actually need to choose 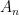 a little more carefully to guarantee that each
a little more carefully to guarantee that each  on the generating collections, it preserves the
on the generating collections, it preserves the  is the only real vector space with dimension
is the only real vector space with dimension 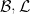 the Borel and Lebesgue
the Borel and Lebesgue  and
and 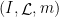 , let us agree to only work with complete measure spaces; this is no great loss, since given an arbitrary metric space
, let us agree to only work with complete measure spaces; this is no great loss, since given an arbitrary metric space 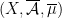 .
.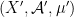 are isomorphic if there is a bijection
are isomorphic if there is a bijection 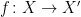 such that
such that  are measurable and
are measurable and 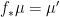 ; that is, given
; that is, given 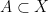 we have
we have 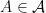 if and only if
if and only if  , and in this case
, and in this case  .
. of all infinite binary sequences, equipped with the Borel
of all infinite binary sequences, equipped with the Borel 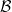 associated to the product topology (or if you prefer, the metric
associated to the product topology (or if you prefer, the metric 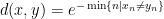 ). Let
). Let  -Bernoulli measure on
-Bernoulli measure on 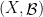 ; that is, for each
; that is, for each 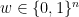 the cylinder
the cylinder ![{[w] = \{x\in X \mid x_1 \cdots x_n = w\}}](https://s0.wp.com/latex.php?latex=%7B%5Bw%5D+%3D+%5C%7Bx%5Cin+X+%5Cmid+x_1+%5Ccdots+x_n+%3D+w%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) gets weight
gets weight ![{\mu[w] = 2^{-n}}](https://s0.wp.com/latex.php?latex=%7B%5Cmu%5Bw%5D+%3D+2%5E%7B-n%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Then there is a natural correspondence between the completion
. Then there is a natural correspondence between the completion  and
and 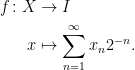
![{[\frac k{2^n}, \frac{k+1}{2^n}] \subset I}](https://s0.wp.com/latex.php?latex=%7B%5B%5Cfrac+k%7B2%5En%7D%2C+%5Cfrac%7Bk%2B1%7D%7B2%5En%7D%5D+%5Csubset+I%7D&bg=ffffff&fg=000000&s=0&c=20201002) one can readily verify that
one can readily verify that 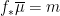 ; however,
; however, 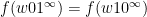 .
.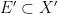 such that
such that 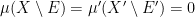 , together with a bijection
, together with a bijection 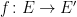 such that
such that 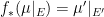 .
.  is clearly an invariant of isomorphism mod 0, and hence we restrict our attention to probability spaces, for which
is clearly an invariant of isomorphism mod 0, and hence we restrict our attention to probability spaces, for which 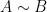 if
if  ; this is an equivalence relation on
; this is an equivalence relation on  for the space of equivalence classes. The function
for the space of equivalence classes. The function  induces a metric
induces a metric 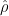 on
on 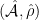 is separable; that is, if it has a countable dense subset.
is separable; that is, if it has a countable dense subset. such that
such that  is the smallest
is the smallest  . We write (CG) for this property; for example, the Borel
. We write (CG) for this property; for example, the Borel 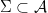 with the property that for every
with the property that for every 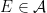 , there is
, there is 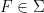 with
with  . In other words, we have
. In other words, we have 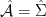 . Note that
. Note that  .
. 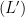 , rendered in a font that I will not attempt to duplicate here.)
, rendered in a font that I will not attempt to duplicate here.) and
and 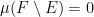 . This is satisfied for
. This is satisfied for 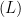 .)
.)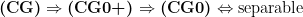
![{\mathcal{A} = \{ A \subset [0,1] \mid A\in \mathop{\mathcal L}, \mu(A)=0 \text{ or } 1\}}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal%7BA%7D+%3D+%5C%7B+A+%5Csubset+%5B0%2C1%5D+%5Cmid+A%5Cin+%5Cmathop%7B%5Cmathcal+L%7D%2C+%5Cmu%28A%29%3D0+%5Ctext%7B+or+%7D+1%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Then
. Then  generated by
generated by 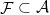 that is dense with respect to
that is dense with respect to  and
and 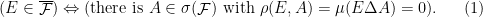
 by proving that
by proving that  is a
is a  ; this will show that (CG0) implies separability.
; this will show that (CG0) implies separability.  : if
: if  then there are
then there are 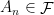 such that
such that 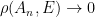 . Since
. Since  and
and  (since it is an algebra), this gives
(since it is an algebra), this gives  .
.
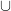 : given
: given  , let
, let 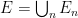 . To show that
. To show that 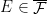 , note that given any
, note that given any 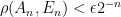 . Let
. Let  and
and 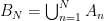 ; note that
; note that

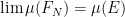 , so
, so 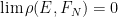 , and thus for sufficiently large
, and thus for sufficiently large 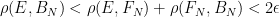 . This holds for all
. This holds for all  , thus proving that
, thus proving that  . Let
. Let 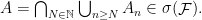 We get
We get 
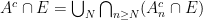 , which gives
, which gives 
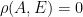 , which completes the proof of
, which completes the proof of  direction) appears in
direction) appears in 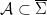 , where
, where  is the completion of
is the completion of 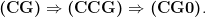
 , and an example satisfying separability (and hence (CG0)) but not (CCG) was given in
, and an example satisfying separability (and hence (CG0)) but not (CCG) was given in 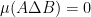 . Although elements of
. Although elements of 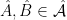 , we choose representatives
, we choose representatives  and
and 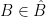 (so
(so  ), and consider the “union” of
), and consider the “union” of  and
and 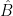 to be the equivalence class of
to be the equivalence class of 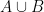 ; write this as
; write this as 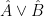 . One can easily check that this is well-defined; if
. One can easily check that this is well-defined; if  and
and 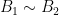 , then
, then 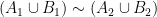 .
. on the space
on the space  induces a binary operation
induces a binary operation  , complementation
, complementation  induces an operation
induces an operation 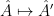 , and set inclusion
, and set inclusion  induces a partial order
induces a partial order 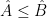 . These give
. These give  , satisfying the same rules as inclusion, union, intersection, and complementation:
, satisfying the same rules as inclusion, union, intersection, and complementation:  is the
is the  (the minimal element such that
(the minimal element such that  ), and
), and 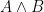 is the
is the 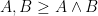 );
);
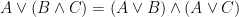 and
and 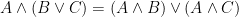 hold;
hold;
 and
and  .
.
 is the unique element satisfying (4) — that is, if
is the unique element satisfying (4) — that is, if  and
and 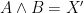 , then
, then  ;
;
 ;
;
 and
and 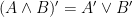 .
.
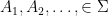 has a least upper bound
has a least upper bound  and a greatest lower bound
and a greatest lower bound 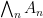 .
.
![{\mu\colon \Sigma\rightarrow [0,\infty]}](https://s0.wp.com/latex.php?latex=%7B%5Cmu%5Ccolon+%5CSigma%5Crightarrow+%5B0%2C%5Cinfty%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is a function satisfying the usual properties:
is a function satisfying the usual properties: 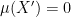 and
and  whenever
whenever 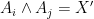 for all
for all  . (Note that
. (Note that  induce a binary operator
induce a binary operator  on
on 
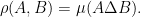
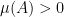 for all
for all 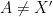 , then this becomes a genuine metric.
, then this becomes a genuine metric.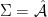 is the space of equivalence classes modulo
is the space of equivalence classes modulo 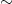 (equivalence mod 0), then
(equivalence mod 0), then ![{\hat{\mathcal{A}} \rightarrow [0,\infty]}](https://s0.wp.com/latex.php?latex=%7B%5Chat%7B%5Cmathcal%7BA%7D%7D+%5Crightarrow+%5B0%2C%5Cinfty%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , which we continue to denote by
, which we continue to denote by 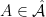 , and so it defines a metric
, and so it defines a metric  , the algebra (
, the algebra ( is the smallest algebra (
is the smallest algebra (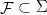 , we have
, we have 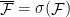 ; that is, the
; that is, the 